

前言
用过 MQ 的同学,可能会遇到过消息堆积的问题。而肥壕最近也踩上了这个坑,但是发现结果竟然是这么一个意料之外的原因而导致的。
正文
那一晚月黑风高,肥壕正准备踏上回家的路,突然收到告警短信轰炸!“MQ 消息堆积告警 [TOPIC: XXX] ”
肥壕心里“万只草泥马崩腾~” 第一反应是:“怎么肥事?刚下班就来搞事情???”

于是乎赶回公司赶紧打开电脑,登上 RocketMQ 后台查看(公司自己搭建的开源版RocketMQ)
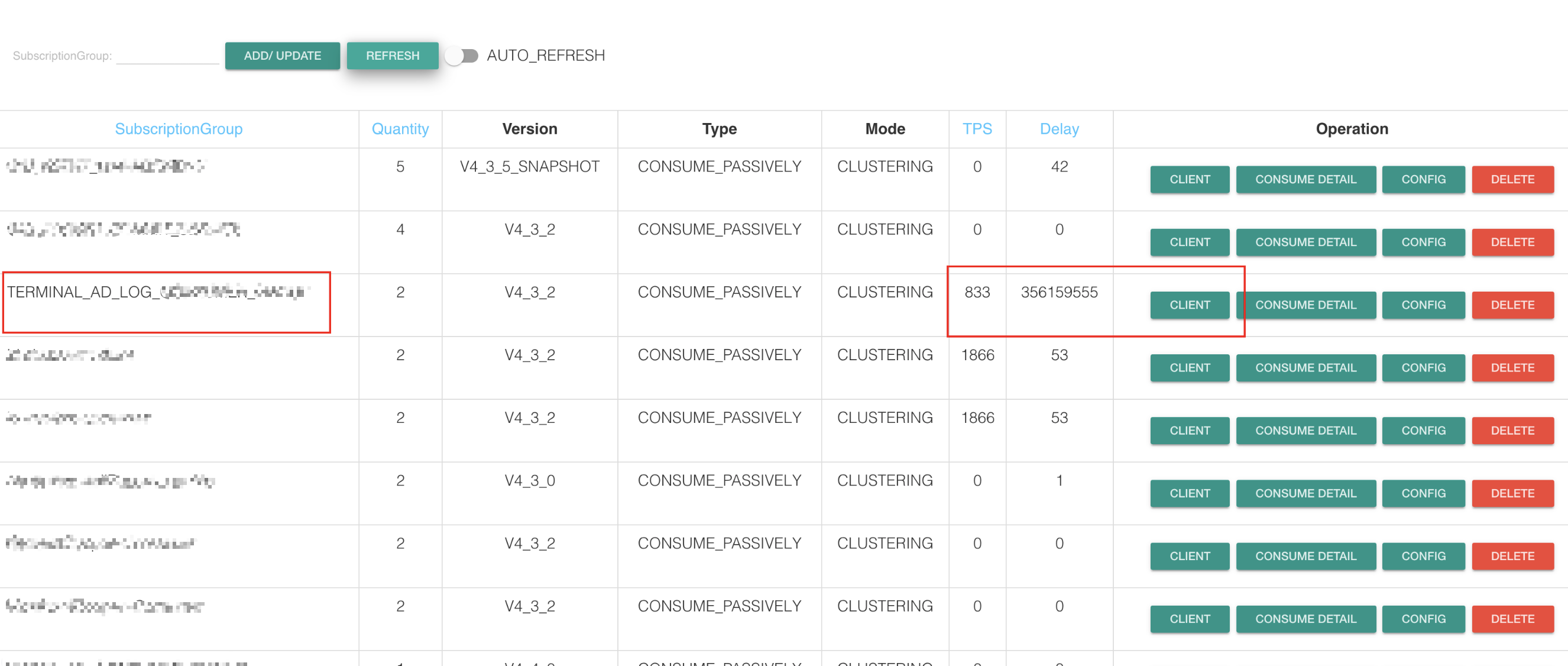
握草 (キ`゚Д゚´)!!! 竟然堆积了3亿多条消息了???
要知道出现消息堆积无在乎这个问题:
生产者的生产速度 >> 消费者的处理速度
- 生产者的生产速度骤增,比如生产者的流量突然骤增
- 消费速度变慢,比如消费者实例 IO 阻塞严重或者宕机
擦了一下头上的冷汗😓...赶紧登上消费者服务器瞧瞧。
应用运行正常!服务器磁盘IO 正常!网络正常!
再去上去生产者的服务器,咦...流量也很正常!
什么???佛了😨 ...生产者和消费者的应用都很正常,但是为什么消息会堆积怎么多呢?看着这堆积的数量越堆越多(要是这是我头发的数量那该多好啊),越发着急。
虽然说 RocketMQ 版能支持 10 亿级别的消息堆积,不会因为消息堆积导致性能明显下降,😰但是这堆积量很明显就是一个异常情况。
RocketMQ 有 BUG,没错这肯定是 RocketMQ 的锅!
本篇完...
哈哈言归正传,虽然肥壕拼爹不行,但至少不能坑爹😂
进入消费者的工程查看一下日志,emmm...没有发现报错,没有错误日志...看起来好像一切都很正常。
咦...不过这个消费的速度是不是有点慢???这不科学啊,消费者可是配置了3个结点的消费集群啊,按业务的需求量来说消费能力可是杠杠的呀。我再点开这个 TOPIC 的消费者信息
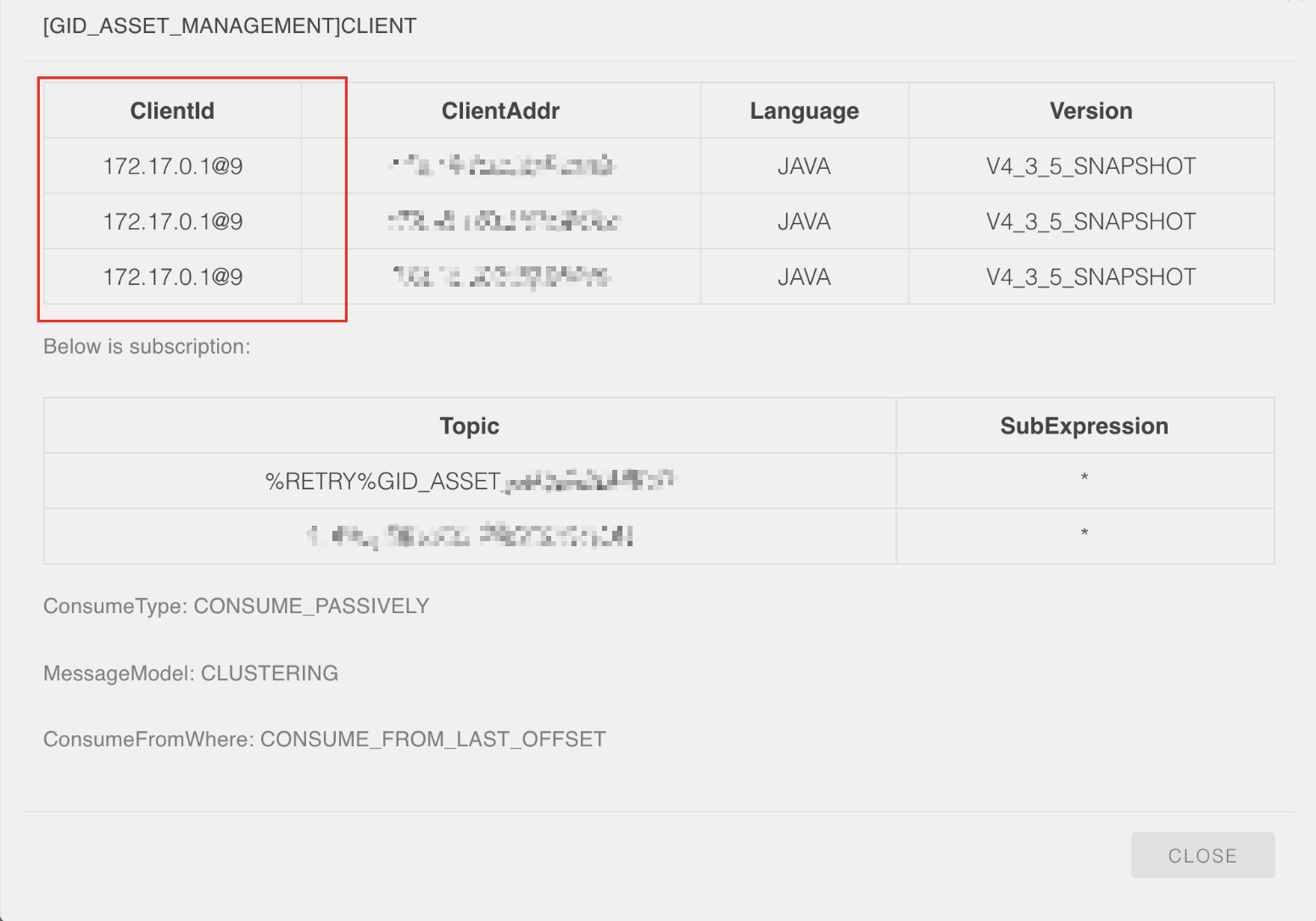
咦,这三个消费者的 ClientId 怎么会是一样呀?
以多年采坑经验的直接告诉我 “难道是因为 ClientId 的相同的问题,导致 broker 在分发消息的时候出现混乱,从而导致消息不能正常推送给消费者?” 因为生产者和消费者都表现正常,所以我猜测问题可能在于 Broker 这一块上。
基于这个推测,那么我们就需要解决这几个问题:
- 部署在不同的服务器上的两个消费者,为什么 ClientId 是相同的呢?
- ClientId 相同,会导致 broker 消息分发错误吗?
问题分析
为什么 ClientId 相同呢?我推测是因为 Docker 容器的问题。因为公司最近开始容器化阶段,而刚好消费者的项目也在第一批容器化阶段的列表上。
有了解过 Docker 的小伙伴都知道,当 Docker 进程启动时,会在主机上创建一个名为docker0的虚拟网桥。宿主机上的 Docker 容器会连接到这个虚拟网桥上。虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连在了一个二层网络中。而 Docker 的网络模式一般有四种:
- Host 模式
- Container 模式
- None 模式
- Bridge 模式
对这几个模式不清楚的同学自行找度娘🤔
我们容器都是采用 Host 模式,所以容器的网络跟宿主机是完全一致的。
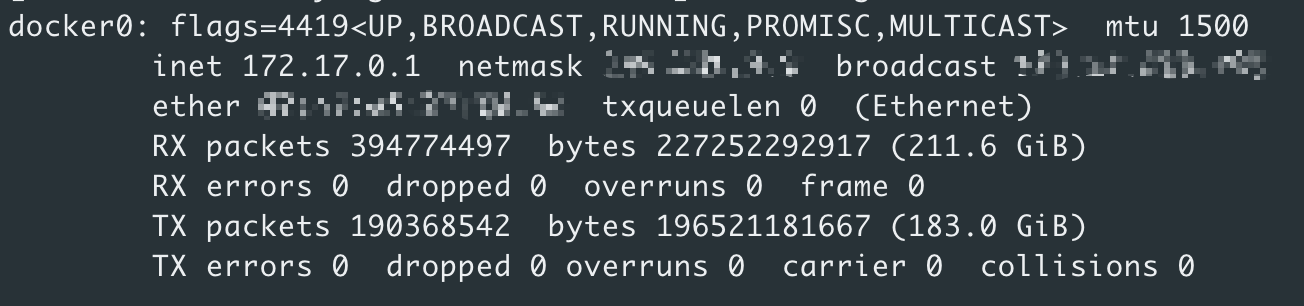
可以看到,这里第一个就是docker0网卡,默认的 ip 都是172.17.0.1。所以显而易见,ClientId 应该读取的都是docker0网卡的 IP,这就是能解释为什么多个消费端的 ClientId 都一致的问题了。
那么接下来就是 clientId 的究竟是在哪里设置呢?机智的我在 Github 的 Issues 搜索关键词 “Docker”,啪啦啪啦一搜,果然!还是有不少踩过次坑的志同道合之士,筛选了一番,找到一个比较靠谱的 open issue
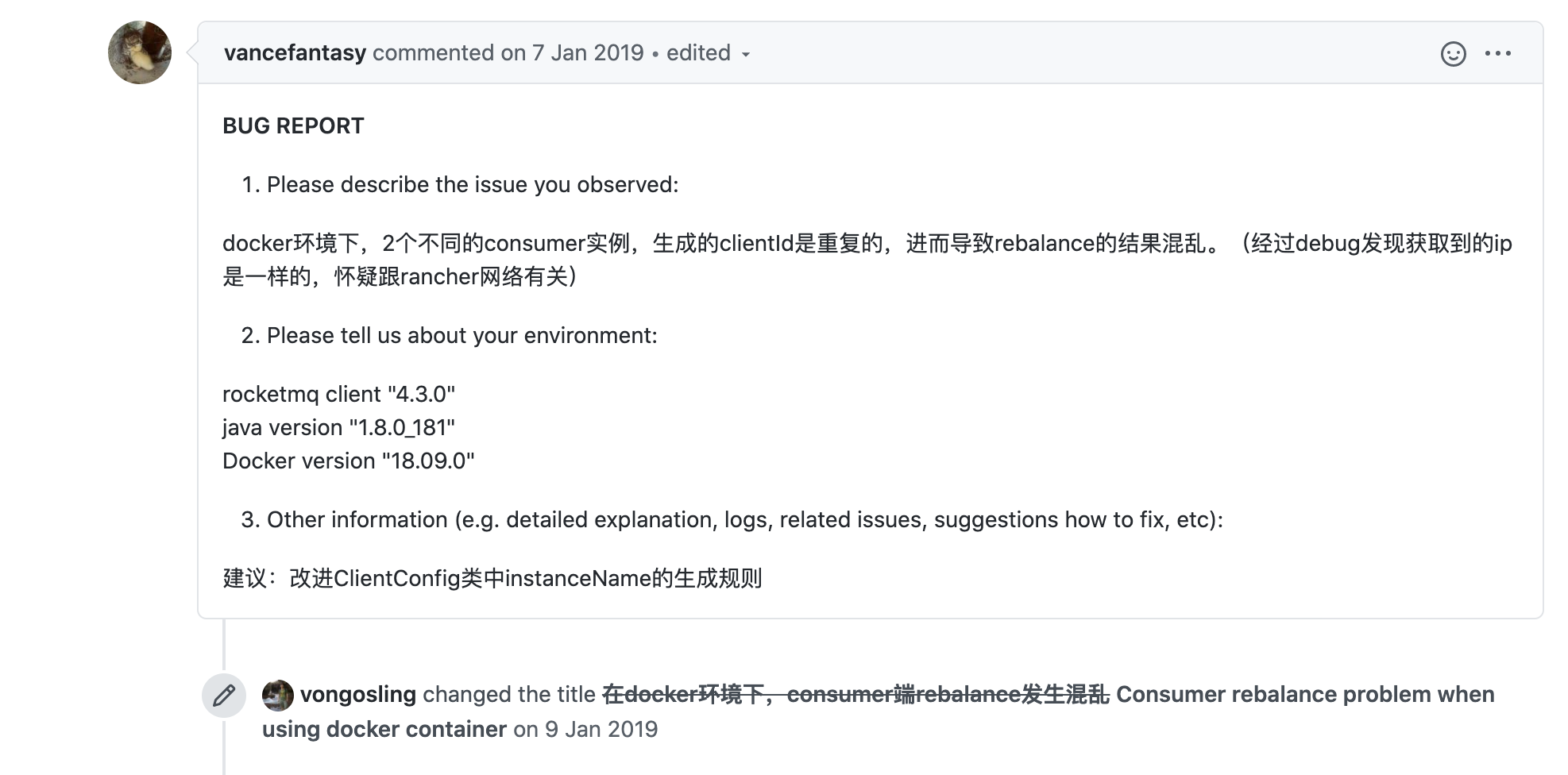
可以看到,这个兄弟跟我的遇到的情况是一毛一样的,而他的结论跟我上面的推测也是大致相同(此时内心洋洋得意一番),他这里还提到 clientId 是在 ClientConfig 类中 buildMQClientId 方法中定义的。
源码探索
进入 ClientConfig 类,定位到 buildMQClientId 方法
public String buildMQClientId() {
StringBuilder sb = new StringBuilder();
sb.append(this.getClientIP());
sb.append("@");
sb.append(this.getInstanceName());
if (!UtilAll.isBlank(this.unitName)) {
sb.append("@");
sb.append(this.unitName);
}
return sb.toString();
}
通过这个相信大家都可以看出 clientId 的生成规则吧,就是 消费者客户端的IP + "@"+ 实例名称,很明显问题就出在获取客户端 IP 上。
我们再继续看一下它究竟是如何获取客户端 IP 的
public class ClientConfig {
...
private String clientIP = RemotingUtil.getLocalAddress();
...
}
public static String getLocalAddress() {
try {
// Traversal Network interface to get the first non-loopback and non-private address
Enumeration<NetworkInterface> enumeration = NetworkInterface.getNetworkInterfaces();
ArrayList<String> ipv4Result = new ArrayList<String>();
ArrayList<String> ipv6Result = new ArrayList<String>();
while (enumeration.hasMoreElements()) {
final NetworkInterface networkInterface = enumeration.nextElement();
final Enumeration<InetAddress> en = networkInterface.getInetAddresses();
while (en.hasMoreElements()) {
final InetAddress address = en.nextElement();
if (!address.isLoopbackAddress()) {
if (address instanceof Inet6Address) {
ipv6Result.add(normalizeHostAddress(address));
} else {
ipv4Result.add(normalizeHostAddress(address));
}
}
}
}
// prefer ipv4
if (!ipv4Result.isEmpty()) {
for (String ip : ipv4Result) {
if (ip.startsWith("127.0") || ip.startsWith("192.168")) {
continue;
}
return ip;
}
return ipv4Result.get(ipv4Result.size() - 1);
} else if (!ipv6Result.isEmpty()) {
return ipv6Result.get(0);
}
//If failed to find,fall back to localhost
final InetAddress localHost = InetAddress.getLocalHost();
return normalizeHostAddress(localHost);
} catch (Exception e) {
log.error("Failed to obtain local address", e);
}
return null;
}
如果有操作过获取当前机器的 IP 的小伙伴,应该对RemotingUtil.getLocalAddress() 这个工具方法并不陌生~
简单说就是获取当前机器网卡 IP,但是由于容器的网络模式采用的是 host 模式,也就意味着各个容器和宿主机都是处于同一个网络下,所以容器中我们也可以看到 Docker - Server 所创建的docker 0网卡,所以它读取的也就是 docker 0网卡所默认的 IP 地址 172.17.0.1
(跟运维同学沟通了一下,目前由于是容器化的第一阶段,所以先采用简单模式部署,后面会慢慢替换成 k8s,每个 pod 都有自己的独立 IP ,到时网络会与宿主机和其他 pod 的相互隔离。emmm....k8s !听起来牛逼哄哄,恰好最近也在看这方面的书)
**这时候聪明的你可能会问 “不是还有一个实例名称的参数呢,这个又怎么会相同呢?” ** 别着急,我们继续往下看👇
private String instanceName = System.getProperty("rocketmq.client.name", "DEFAULT");
public String getInstanceName() {
return instanceName;
}
public void setInstanceName(String instanceName) {
this.instanceName = instanceName;
}
public void changeInstanceNameToPID() {
if (this.instanceName.equals("DEFAULT")) {
this.instanceName = String.valueOf(UtilAll.getPid());
}
}
getInstanceName() 方法其实直接获取 instanceName这个参数值,但是这个参数值是什么时候赋值进去的呢?没错就是通过changeInstanceNameToPID()这个方法赋值的,在 consumer 在 start 的时候会调用此方法。
这个参数的逻辑很简单,在初始化的时候首先会获取环境变量rocketmq.client.name是否有值,如果没有就是用默认值DEFAULT。
然后 consumer 启动的时候会判断这参数值是否为DEFAULT,如果是的话就调用 UtilAll.getPid()。
public static int getPid() {
RuntimeMXBean runtime = ManagementFactory.getRuntimeMXBean();
String name = runtime.getName(); // format: "pid@hostname"
try {
return Integer.parseInt(name.substring(0, name.indexOf('@')));
} catch (Exception e) {
return -1;
}
}
通过方法名字我们就可以很清楚知道,这个方法其实获取进程号的。那...为什么获取的进程号都是一致的呢?

聪明的你可以已经知道答案了对吧🤨 !这里就不得不提 Docker 的 三大特性
- cgroup
- namespace
- unionFS
没错,这里用的就是 namespace 技术啦。
Linux Namespace 是 Linux 内核提供的一个功能,可以实现系统资源的隔离,如:PID、User ID、Network 等。
由于都是使用相同的基础镜像,在最外层都是运行同样的 JAVA 工程,所以我们可以进去容器里面看,他们的进程号都是为 9
经过肥壕的一系列巧妙的推理和论证,在 Docker 容器 HOST 网络模式下, 会生成相同的 clientId !
到这里为止,我们算是解决了上文推测的第一个问题!
紧跟柯南肥壕的步伐,我们继续推理第二个问题: clientId 相同导致 Broker 分发消息错误?
Consumer 在负载均衡的时候应该是根据 clientId 作为客户端消费者的唯一标识,在消息下发的时候由于 clientId 的一致,导致负载分发错误。
那么我们下面就要去探究一下 Consumer 的负载均衡究竟是如何实现的。一开始我以为消费端的负载均衡都是在 Broker 处理的,由Broker 根据注册的 Consumer 把不同的 Queue 分配给不同的 Consumer。但是去看了一下源码上的 doc 描述文档和对源码进行一番的研究后,结果发现自己见识还是太少了(哈哈哈,应该有小伙伴跟我开始的想法是一样的吧)
先来补充一下 RocketMQ 的整体架构
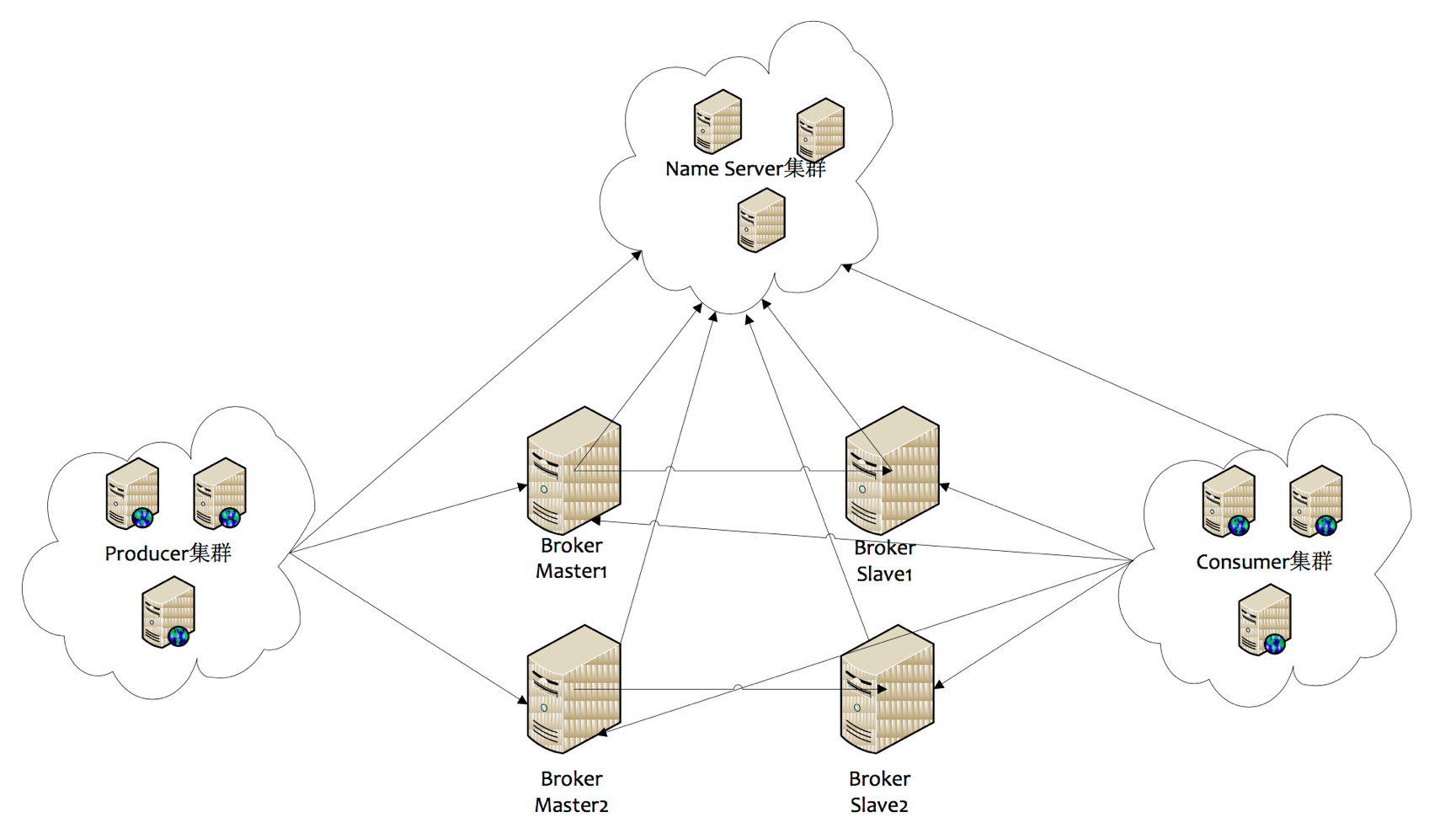
由于篇幅问题,这里我只讲解一下 Broker 和 consumer 之间的关系,其他的角色如果有不懂的可以看一下我之前写的 RocketMQ 介绍篇的文章
- Consumer 与 NameServer 集群中的其中一个节点(随机选择)建立长连接,定期从 NameServer 获取 Topic 路由信息。
- 根据获取 Topic 路由信息 与 Broker 建立长连接,且定时向 Broker 发送心跳。
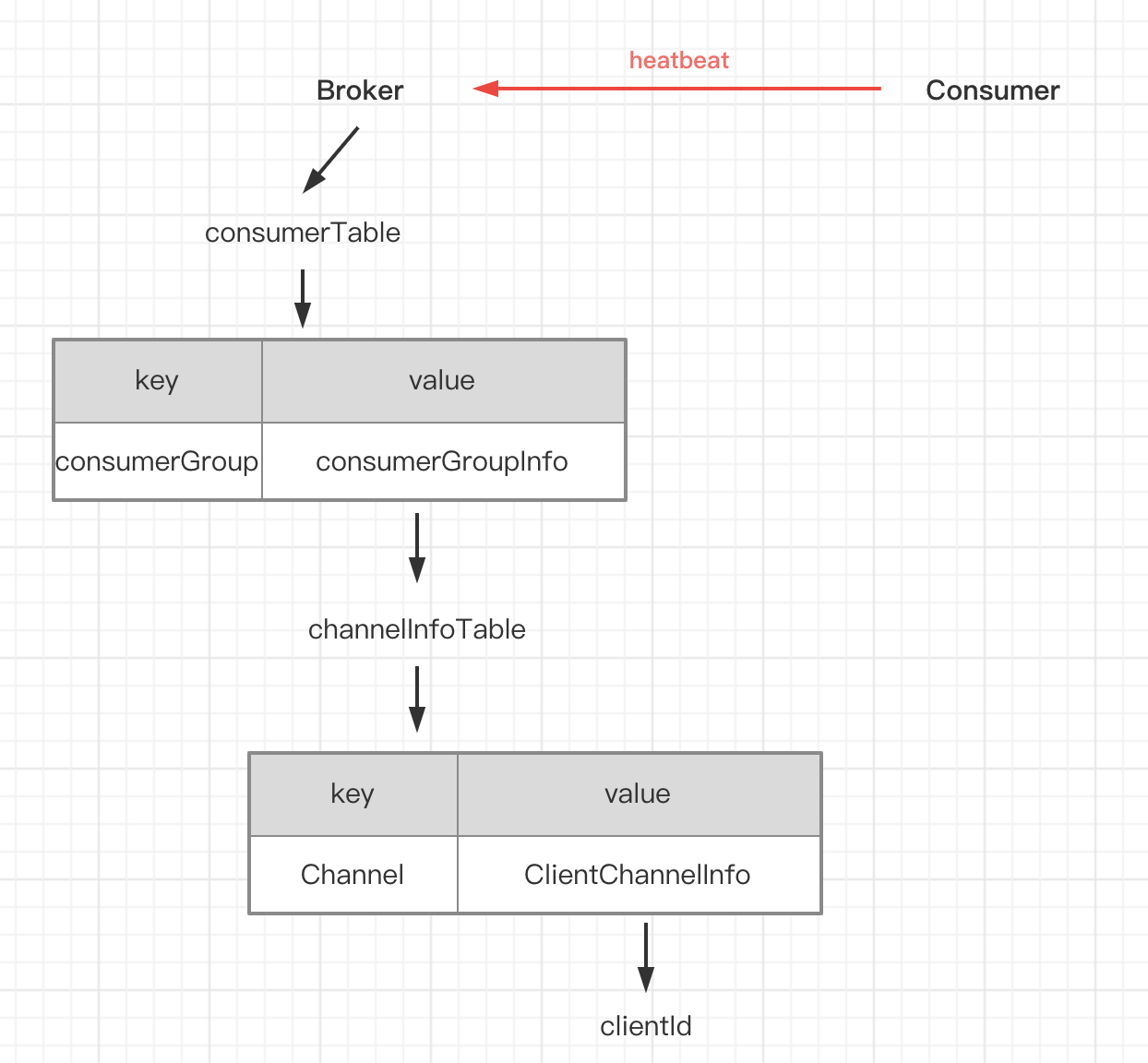
Broker 接收心跳消息的时候,会把 Consumer 的信息保存到本地缓存变量 consumerTable。上图大致讲解了一下 consumerTable 的存储结构和内容,最主要的是它缓存了每个 consumer 的 clientId。
关于 Consumer 的消费模式,我直接引用源码的解释
在 RocketMQ 中,Consumer 端的两种消费模式(Push/Pull)都是基于拉模式来获取消息的,而在 Push 模式只是对 Pull 模式的一种封装,其本质实现为消息拉取线程在从服务器拉取到一批消息后,然后提交到消息消费线程池后,又“马不停蹄”的继续向服务器再次尝试拉取消息。如果未拉取到消息,则延迟一下又继续拉取。
在两种基于拉模式的消费方式(Push/Pull)中,均需要 Consumer 端在知道从 Broker 端的哪一个消息队列—队列中去获取消息。因此,有必要在 Consumer 端来做负载均衡,即 Broker 端中多个 MessageQueue 分配给同一个ConsumerGroup 中的哪些 Consumer 消费。
所以简单来说,不管是 Push 还是 Pull 模式,消息消费的控制权在 Consumer 上,所以 Consumer 的负载均衡实现是在 Consumer 的 Client 端上。
通过查看源码可以发现, RebalanceService 会完成负载均衡服务线程(每隔20s执行一次),RebalanceService 线程的run() 方法最终调用的是 RebalanceImpl 类的 rebalanceByTopic()方法,该方法是实现 Consumer 端负载均衡的核心。这里,rebalanceByTopic()方法会根据消费者通信类型为“广播模式”还是“集群模式”做不同的逻辑处理。这里主要来看下集群模式下的主要处理流程:
private void rebalanceByTopic(final String topic, final boolean isOrder) {
switch (messageModel) {
case BROADCASTING: {
..... // 省略
}
case CLUSTERING: {
// 获取该Topic主题下的消息消费队列集合
Set<MessageQueue> mqSet = this.topicSubscribeInfoTable.get(topic);
// 向 broker 获取消费者的clientId
List<String> cidAll = this.mQClientFactory.findConsumerIdList(topic, consumerGroup);
if (null == mqSet) {
if (!topic.startsWith(MixAll.RETRY_GROUP_TOPIC_PREFIX)) {
log.warn("doRebalance, {}, but the topic[{}] not exist.", consumerGroup, topic);
}
}
if (null == cidAll) {
log.warn("doRebalance, {} {}, get consumer id list failed", consumerGroup, topic);
}
if (mqSet != null && cidAll != null) {
List<MessageQueue> mqAll = new ArrayList<MessageQueue>();
mqAll.addAll(mqSet);
Collections.sort(mqAll);
Collections.sort(cidAll);
// 默认平均分配算法
AllocateMessageQueueStrategy strategy = this.allocateMessageQueueStrategy;
List<MessageQueue> allocateResult = null;
try {
allocateResult = strategy.allocate(
this.consumerGroup,
this.mQClientFactory.getClientId(),
mqAll,
cidAll);
} catch (Throwable e) {
log.error("AllocateMessageQueueStrategy.allocate Exception. allocateMessageQueueStrategyName={}", strategy.getName(),
e);
return;
}
Set<MessageQueue> allocateResultSet = new HashSet<MessageQueue>();
if (allocateResult != null) {
allocateResultSet.addAll(allocateResult);
}
boolean changed = this.updateProcessQueueTableInRebalance(topic, allocateResultSet, isOrder);
if (changed) {
log.info(
"rebalanced result changed. allocateMessageQueueStrategyName={}, group={}, topic={}, clientId={}, mqAllSize={}, cidAllSize={}, rebalanceResultSize={}, rebalanceResultSet={}",
strategy.getName(), consumerGroup, topic, this.mQClientFactory.getClientId(), mqSet.size(), cidAll.size(),
allocateResultSet.size(), allocateResultSet);
this.messageQueueChanged(topic, mqSet, allocateResultSet);
}
}
break;
}
default:
break;
}
}
(1) 从本地缓存变量 topicSubscribeInfoTable 中,获取该Topic主题下的消息消费队列集合(mqSet);
(2) 根据 topic 和 consumerGroup 为参数调用findConsumerIdList()方法向 Broker 端发送获取该消费组下 clientId 列表;
(3) 先对 Topic 下的消息消费队列、消费者Id排序,然后用消息队列分配策略算法(默认为:消息队列的平均分配算法),计算出待拉取的消息队列。这里的平均分配算法,类似于分页的算法,将所有 MessageQueue 排好序类似于记录,将所有消费端 Consumer 排好序类似页数,并求出每一页需要包含的平均 size 和每个页面记录的范围 range,最后遍历整个range 而计算出当前 Consumer 端应该分配到的记录(这里即为:MessageQueue)。
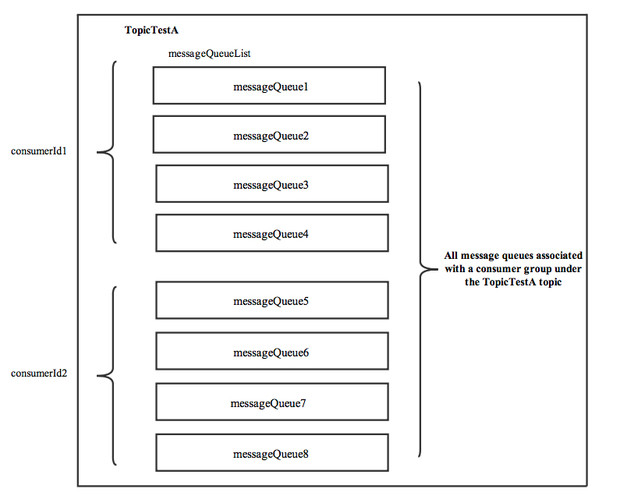
(4) 然后,调用updateProcessQueueTableInRebalance()方法,具体的做法是,先将分配到的消息队列集合(mqSet)与processQueueTable做一个过滤比对。
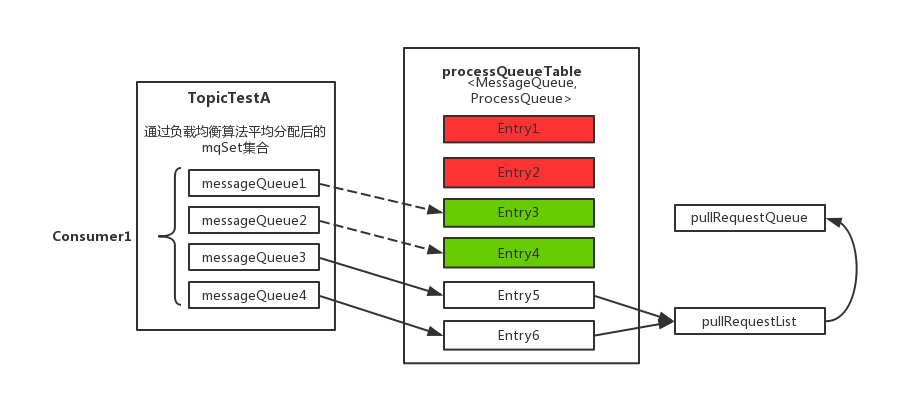
- 上图中 processQueueTable 标注的红色部分,表示与分配到的消息队列集合 mqSet 互不包含。将这些队列设置Dropped 属性为 true,然后查看这些队列是否可以移除出 processQueueTable 缓存变量,这里具体执行
removeUnnecessaryMessageQueue()方法,即每隔1s 查看是否可以获取当前消费处理队列的锁,拿到的话返回true。如果等待1s后,仍然拿不到当前消费处理队列的锁则返回false。如果返回true,则从 processQueueTable 缓存变量中移除对应的 Entry; - 上图中 processQueueTable 的绿色部分,表示与分配到的消息队列集合 mqSet 的交集。判断该 ProcessQueue 是否已经过期了,在Pull模式的不用管,如果是 Push 模式的,设置 Dropped 属性为 true,并且调用
removeUnnecessaryMessageQueue()方法,像上面一样尝试移除 Entry;
消息消费队列在同一消费组不同消费者之间的负载均衡,其核心设计理念是在一个消息消费队列在同一时间只允许被同一消费组内的一个消费者消费,一个消息消费者能同时消费多个消息队列。
上面这部分内容是摘自RocketMQ 源码中 docs的文档,不知道你们看懂了没,反正我是看了好几遍才理解了🤔🤔🤔
其实看步骤3的图,负载均衡的实现原来也就一目了然了,简单说就是给不同的消费者分配数量相同的消费队列。而消费者都会生成 clientId 的唯一标识,但是根据我们上文的推理,在容器中并且是Host网络模式下会生成一致的 clientId。
Emmmm....到这里,想必大家都能猜到究竟是哪里出问题了吧。
没错!问题应该就出在步骤3中,平均分配的计算方式。
@Override
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll, List<String> cidAll) {
if (currentCID == null || currentCID.length() < 1) {
throw new IllegalArgumentException("currentCID is empty");
}
if (mqAll == null || mqAll.isEmpty()) {
throw new IllegalArgumentException("mqAll is null or mqAll empty");
}
if (cidAll == null || cidAll.isEmpty()) {
throw new IllegalArgumentException("cidAll is null or cidAll empty");
}
List<MessageQueue> result = new ArrayList<MessageQueue>();
if (!cidAll.contains(currentCID)) {
log.info("[BUG] ConsumerGroup: {} The consumerId: {} not in cidAll: {}",
consumerGroup,
currentCID,
cidAll);
return result;
}
// 当前clientId所在的下标
int index = cidAll.indexOf(currentCID);
int mod = mqAll.size() % cidAll.size();
int averageSize =
mqAll.size() <= cidAll.size() ? 1 : (mod > 0 && index < mod ? mqAll.size() / cidAll.size()
+ 1 : mqAll.size() / cidAll.size());
int startIndex = (mod > 0 && index < mod) ? index * averageSize : index * averageSize + mod;
int range = Math.min(averageSize, mqAll.size() - startIndex);
for (int i = 0; i < range; i++) {
result.add(mqAll.get((startIndex + i) % mqAll.size()));
}
return result;
}
上面的计算可以看起来有点绕,但是其实看懂了之后,说白就是计算当前 Consumer 所分配的消息队列,就好比上图步骤3中的图示
假设当前只有一个 consumer ,那我们的消费其实是完全正常的,因为当前 Topic 下所有的队列都会分配给当前的 consumer ,也不存在负载均衡的问题。
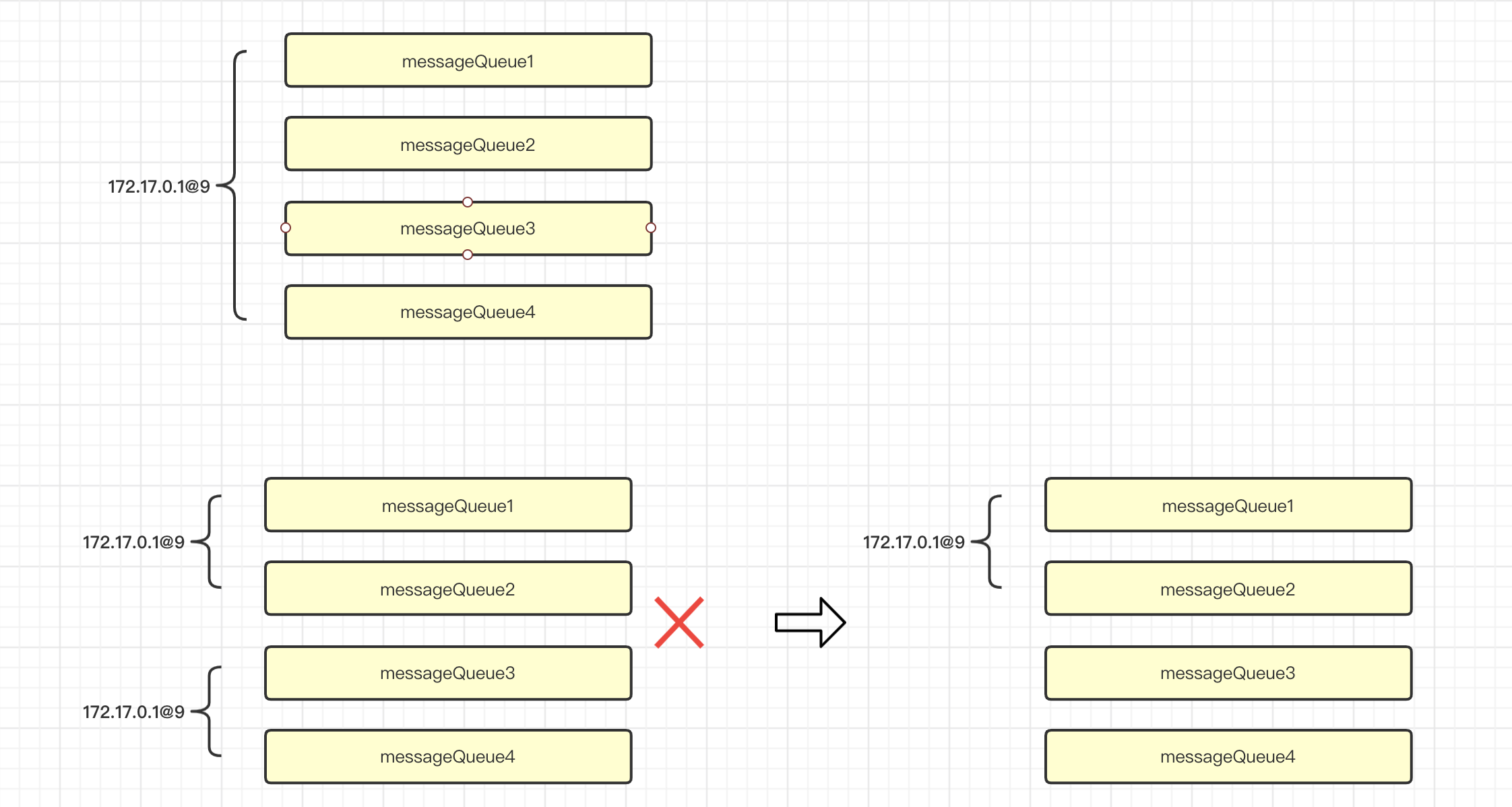
假设当前有两个 consumer,按照正常的计算方式结果应该是这样子的。但是因为cidAll是两个重复的 clientId,所以两个 consumer 获得的 index 都是0,自然他们分配的都是相同的 MessageQueue。这就能解释开头为什么能看到是有消费的日志,但是消费速度非常慢的原因了。
解决方法
- 解决负载均衡错误
罪魁祸首:clientId
经过一翻精彩的推论,大家应该知道导致 Consumer 负载均衡错误的根本原因就是Consumer 客户端生成的 clientId 一致,所以解决这个问题重点就是在于修改 clientId 的生成规则。上面简单地从源码分析了一下 clientId 的生成规则 ,我们可以通过手动设置 rocketmq.client.name 这个环境变量,生成自定义唯一的 clientId 。
肥壕这里在原来的 pid 后再加上了时间戳:
@PostConstruct
public void init() {
System.setProperty("rocketmq.client.name", String.valueOf(UtilAll.getPid()) + "@" + System.currentTimeMillis());
}
- 解决消息堆积
终于解决了根本问题了!行吧,万事俱备只差上线,队列里头堆积的3亿多条消息还在等着消费呢。
(可谓是一时堆积一时爽,一直堆积一直爽😭)
刚上线了不久,emmm...效果显著,堆积的消息数量逐渐减少了。但是另外一个告警来了,mongodb 告警了!
握草。。。我差点忘记了,消费者对消息业务处理后后会写入mongodb,现在消费的流量入口突然骤增,mongodb反倒扛不住了。不过还好历史的消息不重要,是可以丢失的。于是肥壕果断去后台重置了一下消费点位,妥了现在消费正常了,mongodb也正常了。呼~有惊无险,差点又酿造了另外一起事故。
总结
- RocketMQ 的 consumer 客户端都会生成 clientId 唯一标识,clientId 的生成规则是
客户端IP+客户端进程号 - Docker 容器部署如果网络模式使用 Host 模式,容器中的应用都会获取 Docker 网桥的默认IP
- RocketMQ 的 consumer 端负载均衡是在客户端实现的,consumer 客户端会缓存对应的 Topic 消费队列,默认采用消息队列的平均分配算法,如果 clientId 相同那么所有的客户端都会分配到相同的队列,导致消费异常。
- 对于消息堆积的处理,要做好全面的检查。不能被瞬间大流量的消费入口而影响其他业务,不然就像肥壕一样搞出另一起事故了(大家如果有更好的消息堆积处理方案欢迎留言提议)
这次是肥壕第一次写有关线上事故的文章,可能很多地方或者细节上比较粗糙,望各位广大猿友多体谅多提建议哈~
经历过的线上事故其实还不少,但是每次总结都是流于形式,希望从今以后能用文章的形式整理出来,一是有助于自己日后的总结复盘,也能给大家提供更多的采坑经验。
普通的改变,将改变普通
我是宅小年,一个在互联网低调前行的小青年
关注公众号「宅小年」,个人博客 📖 edisonz.cn,阅读更多分享文章
