

今天来简单聊一聊短链服务。
最近小年的项目中需要使用到短链,需求背景大致是这样:用户在页面上生成分享链接,并且可以把链接和内容分享给其他用户。
分享的方式有短信、其他三方平台比如为 Wechat、Facebook、Twitter 等。
而生成短链的目的也很简单,第一个肯定是为了看起来更简洁,分享的链接可能会携带各种参数之类;第二个是省钱,因为短信的费用跟内容长短有关,内容越长可能费用就越多;第三个是适用多平台,一些三方平台的分享内容会有长度限制;

跳转原理
短链跳转的实现原理其实很简单,简单概括就是:重定向!
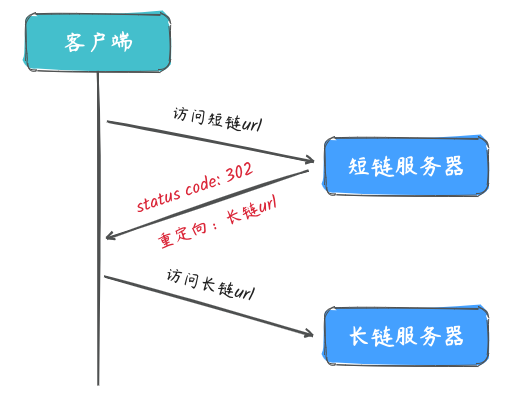
HTTP状态码:3XX
这类状态码代表需要客户端采取进一步的操作才能完成请求。通常,这些状态码用来重定向,后续的请求地址(重定向目标)在本次响应的Location域中指明。
一般来说,短链服务都是使用302实现重定向,因为可以利用短链来统计访问数量之类的数据。
小年直接贴一个ChatGPT的回答🔍

生成短链
短链的生成方式常见的有两种
- 哈希算法,核心其实就是对长链进行哈希算法,生成唯一的
Hash Code。 - 发号器,可以理解为是分布式ID自增生成器,为每一个长链分配一个唯一的ID。
小年项目选用的是哈希算法,也比较推荐哈希算法。一个是实现起来比较简单,另外一个是哈希算法生成的短链比较无规则,跟我们平时收到的营销短信比较类似。

当然具体场景还是要具体分析,发号器的方案也有它的优点

不过小年这里主要讲一下哈希算法。
网上推荐最多的是 MurmurHash 算法,对比我们常用的 MD5、SHA这类哈希算法来说,最大的优势就是快!
MurmurHash 是一种非加密的高效哈希算法,由 Austin Appleby 于 2008 年开发。该算法因其高性能、均匀分布和较低的碰撞率,成为了很多高效数据处理场景的首选,特别是在哈希表、缓存、分布式系统和大数据处理中,同时也是许多知名公司和框架的首选散列算法。
MurmurHash 的特点
- 高性能:MurmurHash 的计算速度非常快,特别适合大规模数据处理的场景。其高效性得益于简单的位运算和乘法操作。
- 非加密:MurmurHash 不是为加密设计的,因此不能保证数据的安全性。但它的目标是快速生成散列值,而不需要复杂的安全计算。
- 良好的分布性:MurmurHash 生成的散列值分布均匀,碰撞率低,这对于需要分散存储数据的场景非常关键,比如哈希表或分布式存储系统。
- 多版本:
- MurmurHash2:该版本广泛使用,适合32位系统。
- MurmurHash3:是当前的主流版本,改进了前两个版本中的一些弱点,适用于64位和128位的需求,并提供更强的哈希质量。
MurmurHash 与其他哈希算法的对比
- 与 MD5、SHA-1 比较:
- MurmurHash 比这些加密哈希函数更快,因为它不需要执行复杂的安全计算。MD5 和 SHA 系列哈希算法主要用于数据完整性验证和安全需求,而 MurmurHash 侧重于速度和分布性。
- 与 CityHash 和 xxHash 比较:
- CityHash 和 xxHash 是两个速度和性能相当接近 MurmurHash 的哈希函数。CityHash 由 Google 开发,专注于更大的输入集。xxHash 在某些场景下可能比 MurmurHash 更快,但 MurmurHash 的兼容性和稳定性让它依然被广泛使用。

MurmurHash 提供了两种长度的哈希值,32 bit,128 bit, 32 bit 可以表示 42.9 亿的数据,基本能够应付我们常见的业务场景了。
当然,为了能够得到极致简短的短链,还可以将哈希值进行62进制的转换。
public static void main(String[] args) {
String rawUrl = "http://edisonz.cn/archives/groovy";
HashFunction hashFunction = Hashing.murmur3_32();
HashCode hashCode = hashFunction.hashString(rawUrl, StandardCharsets.UTF_8);
System.out.println(hashCode.asInt());// 1936285200
System.out.println(hashCode);// 105e6973
System.out.println(intToBase64(hashCode.asInt()));// 1PqlUg
}
哈希冲突,这个问题也比较好解。不同长链哈希值一致的情况,可以在长链中加入**“盐值”(salt)**后再做哈希,访问的时候再移除掉 salt,就是正常的长链。
高性能架构
当然,上面仅仅是短链服务的一个理论和实现原理,要设计一个能够真正应用于实际业务场景的企业级短链服务,还有很多细节点需要我们去思考和挖掘的。
而且这也是一道高频的面试问题,相信有同学可能碰到过:如何设计一个高性能的短链服务。
小年就个人的看法简单分享一下,要是有不足的地方可以补充哈
小年就从两个维度来简单分享自己的一个看法,当然有建议或者不足的地方欢迎大家改正和补充~
数据层
- 分库分表:确定未来周期内的数据增长量,是否需要采取分库分表;
- 读写分离:评估读写的并发流量。一般来说是读流量远大于写流量,可以采用读写分离;
- 过期时间:短链是否存在过期时间,对于过期的数据需要定时清理还是归档;
应用层
- 缓存:对热点数据开启缓存,减少数据库的访问,这应该是性能提效比较显著的一招。二级缓存和三级缓存都可以结合场景使用起来,比如 Redis和本地缓存。
- 布隆过滤器:每个长链生成的短链在数据库中是唯一的,所以在生成短链后需要先去数据库查询。引入 Redis 布隆过滤器可以减轻在判断短链重复校验的数据库压力。当然,对于创建短链也就是写流量并发高的场景效果最好,但需要自己维护 Redis 布隆过滤器。
十分钟,部署一个短链服务
相信看完上面的内容后,大家对短链
看过小年上面的分享后,相信大家对短链也有一定程度的了解。
短链的原理和整体实现其实并不复杂,小年使用 Next.js 实现了一个简单易用的短链服务。
有兴趣的同学可以了解一下:十分钟!免费部署一个自己的短链服务!
Demo 体验:https://slink-code.vercel.app/
