

最近业务碰到个需求,要每个消费实例都要消费到消息。可能聪明的亚子一看就想到,用广播模式不就得了。
没错,小年一开始也是想到一块了。
于是就研究一下 Kafka 的广播模式是怎么用的。结果一搜才发现,原来 Kafka 的广播模式,就是为每个实例配置不同的消费组ID(GroupId),即每个实例都是单独的消费组。
但kafka消费者的配置信息都是走配置中心的,如果要每个实例都不一样,那代码得要怎么写?
当然,神通广大的网友们已经想到办法了:
@KafkaListener注解的GroupId属性支持SpEL表达式,可以通过这个实现每个应用实例都是单独的消费组,进而实现广播消费。
下面表达式指的是取值java.util.UUID这个类的randomUUID方法,当然也可以通过后缀当前机器ip的方式实现动态groupId
@KafkaListener(topics = {"topic"}, properties = {"auto.offset.reset=latest"},
groupId = "consumerGroup-" + "#{T(java.util.UUID).randomUUID()}")
等等,有点不对劲,小年突然想起,RocketMQ 就能支持同一个消费组下,实现广播模式的呀。
看了一下使用的姿势,果然:
// 声明并初始化一个 consumer
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("comsumer");
consumer.setNamesrvAddr("127.0.0.1:9876");
// 设置广播模式
consumer.setMessageModel(MessageModel.BROADCASTING);
那么问题来了,为什么 RocketMQ 能够支持同一个消费组的广播模式呢,它是如何实现的呢?
带着问题先思考一下,要实现广播模式,也就是说每个消费实例节点,都必须消费 Topic 的所有消息。
在 RocketMQ 中 Topic 会被分成多个 queue,而这么做的目的就是为了负载均衡。
假设是集群模式下,同一个消费组下的多个消费实例,会分摊 topic 上的消息。
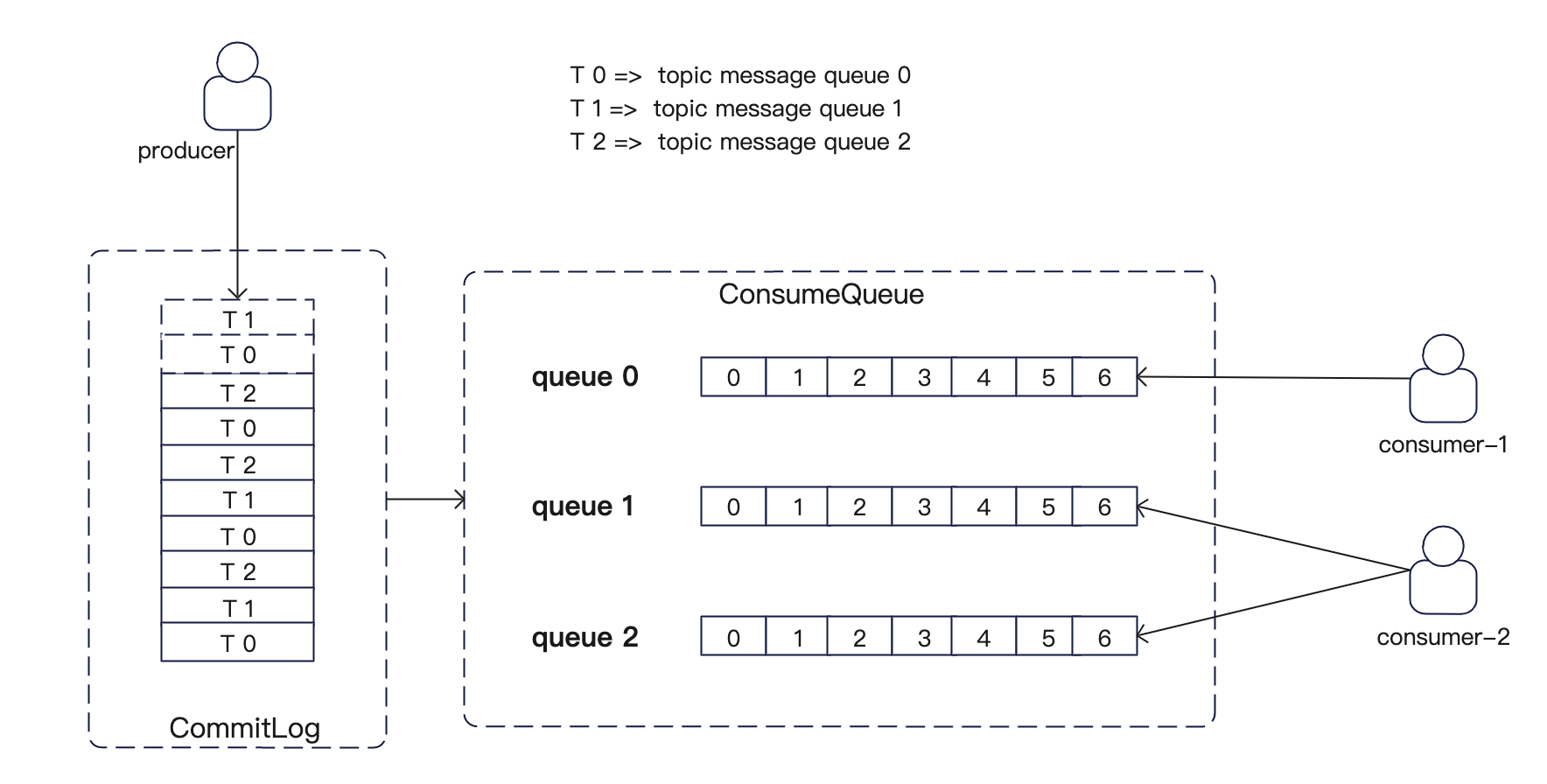
如果是广播模式,那么就会变成这样:
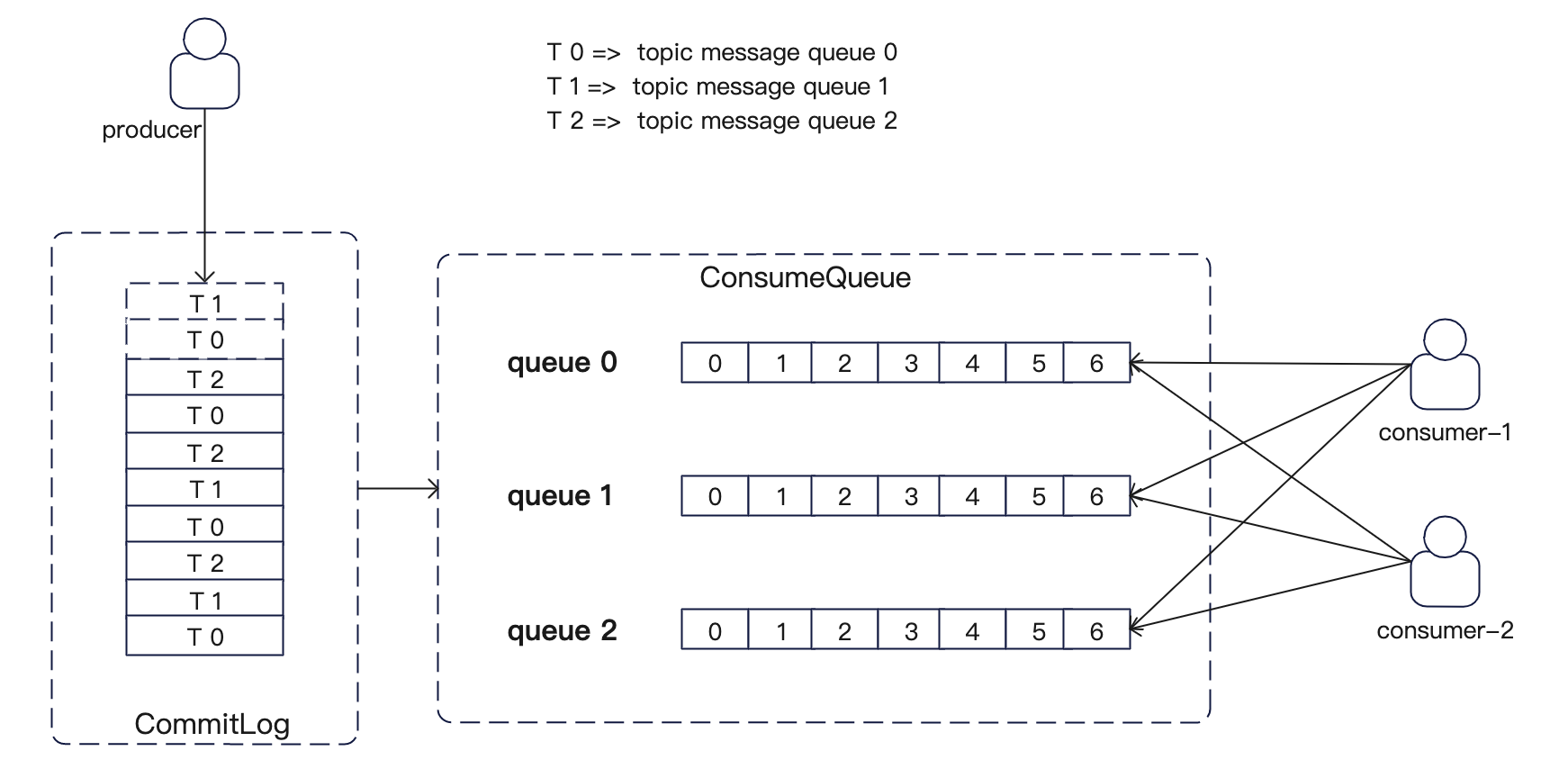
(这里的queue,实际上是 consumeQueue,而 topic 划分的 queue 实际上都会写到 commitLog 中,只不过会保留 queue的信息)
那么这里其实就是客户端的负载均衡,如果没猜错的话,如果 MessageModel 如果是 BROADCASTING,那么消费实例就会分配所有的queue。
于是,小年本着务实求真,果断手撕源码,确实如此。
RebalanceImpl.java
private void rebalanceByTopic(final String topic, final boolean isOrder) {
switch (messageModel) {
case BROADCASTING: {
Set<MessageQueue> mqSet = this.topicSubscribeInfoTable.get(topic);
if (mqSet != null) {
boolean changed = this.updateProcessQueueTableInRebalance(topic, mqSet, isOrder);
if (changed) {
this.messageQueueChanged(topic, mqSet, mqSet);
log.info("messageQueueChanged {} {} {} {}",
consumerGroup,
topic,
mqSet,
mqSet);
}
} else {
log.warn("doRebalance, {}, but the topic[{}] not exist.", consumerGroup, topic);
}
break;
}
case CLUSTERING: {
.....
break;
}
default:
break;
}
}
代码逻辑还比较简单,这里就不详细讲了。