

背景
需求要根据商家名称、经纬度对商家列表进行地理位置检索和全文检索,目前这部分数据是缓存在 MongoDB 上,虽然说 MongoDB 支持全文索引,但是对于中文检索,MongoDB 似乎做的还不是非常好,线上也会经常出现查询超时的情况。所以经过考虑研究后,决定改用 Elasticsearch 作为搜索引擎。
目前线上的百万数据需要同步到 Elasticsearch,那么如何能够安全又快速的实现大数据量的同步呢?
方案验证
测试数据量: 200w
方案一:单线程同步
| 线程数 | 耗时 |
|---|---|
| 1 | 1h |
单线程跑对于应用来说是非常安全的,但是在时间效率上,确实不太能容忍。
方案二:多线程
把同步数据分成多份,使用多线程同步
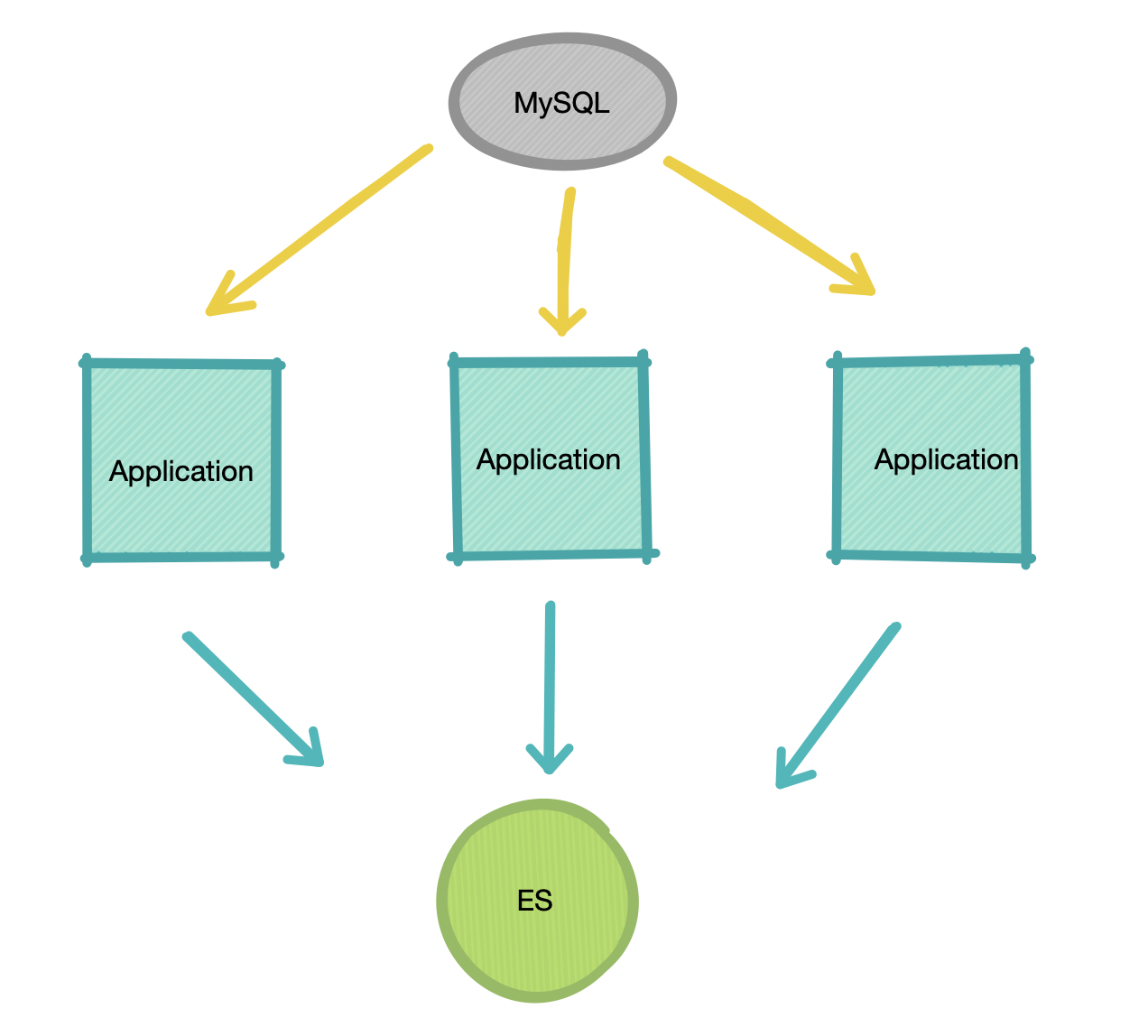
与上面单线程相比,这个速率可以说是一个质的飞跃。
| 线程数 | 耗时 |
|---|---|
| 4 | 5 min |
| 5 | 4 min |
| 8 | 2.5 min |
| 16 | 1.6 min |
线程类型分为:CPU 密集型 、 IO 密集型
很显然这是属于 IO 类型,瓶颈应该是在 MySQL 和 ES 的 IO 上,所以理论上线程数越多处理速度越快,这也跟上面的数据符合一致。
当然也不是线程数越多越好,CPU 核数就那么几个,线程数多了上下文切换的耗时也会增加,应用的其他业务也会被影响到。所以在全局的考虑下,选择最合适的 8 个线程数。
因为要等待所有的线程数完成任务,才算是完成整个同步的任务。这里使用了 CountDownLatch 作为计数器:
countDownLatch = new CountDownLatch(8);
taskExecutor.submit(() -> {
try {
// 业务逻辑
doSomething();
} finally {
countDownLatch.countDown();
}
});
countDownLatch.await();
log.info("task done!");
当然,在这个过程中还遇到 RestHighLevelClient 抛出的一个异常:
Caused by: java.util.concurrent.TimeoutException: Connection lease request time out
RestHighLevelClient 的底层其实是 HttpClient ,如果有使用过 HttpClient 的同学,看到这个异常应该也不陌生。
这里有三个比较重要的参数:
- connectionRequestTimout 从连接池获取连接的timeout
- connetionTimeout 客户端和服务器建立连接的timeout
- socketTimeout 客户端和服务器建立连接后,客户端从服务器读取数据的timeout
很显然 connectionRequestTimout 配置的超时时间太短了,后面边改为 10 s 就解决了这个问题。
方案三:多线程+多线程
要知道整个同步过程其实就是 :
- 读取 MySQL 数据
- 写入 ES
肥壕打印了这两个步骤的耗时,发现步骤二的占用时间是70%-80%,那有办法能够提高步骤二的速度吗?
肥壕这时有个大胆的想法,如果把步骤二也分成多个线程呢?
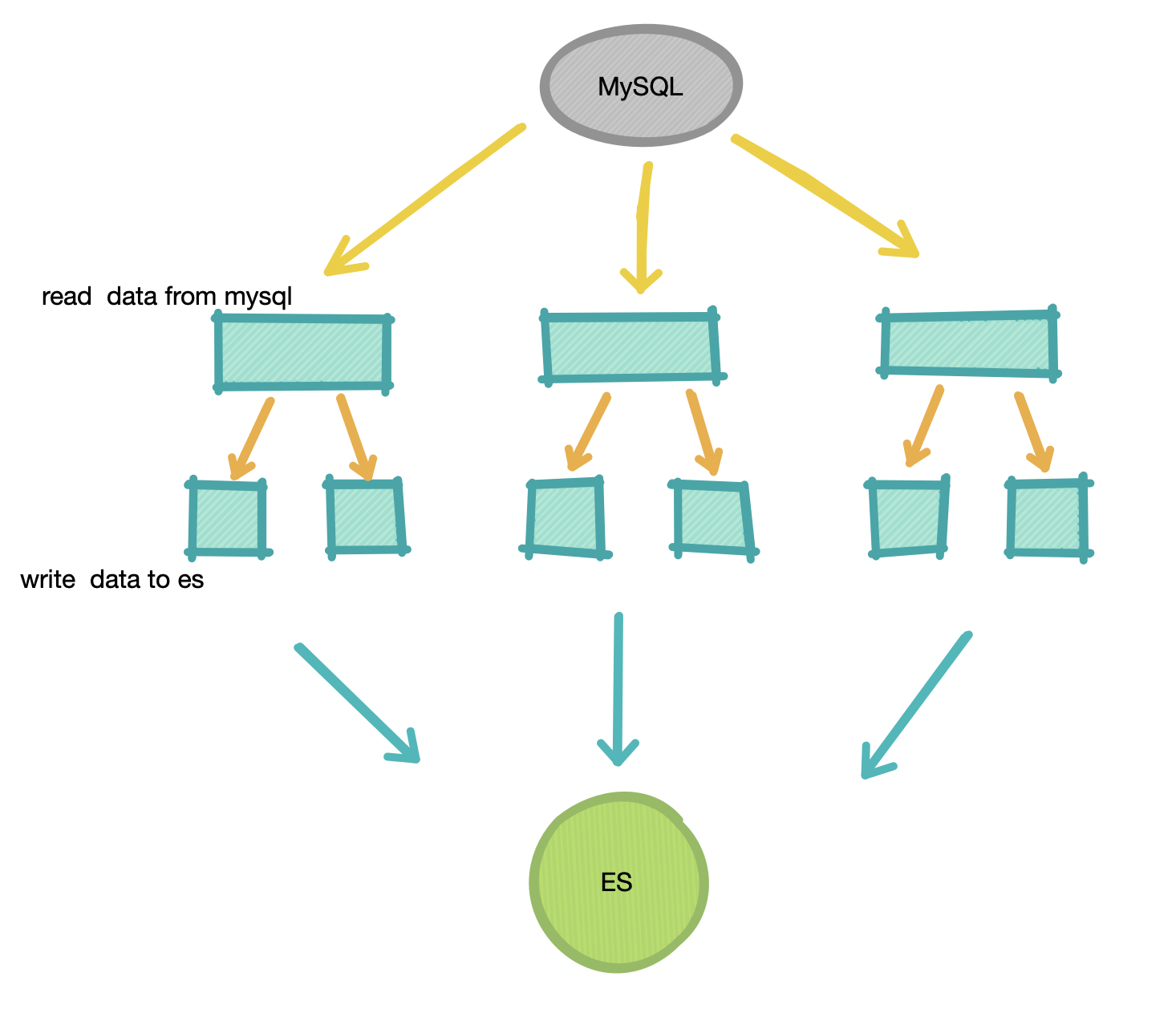
这里使用 Semaphore 来控制 ES写入的并发线程数:
doSomething() {
Semaphore semaphore = new Semaphore(2);
try {
semaphore.acquire();
taskExecutor.submit(() -> {
// ES写入
write2Es()
semaphore.release();
});
} catch (InterruptedException e) {
e.printStackTrace();
}
}
| ES 写入线程数 | 耗时 |
|---|---|
| 2 | 1.5 min |
| 4 | 1.3 min |
(8 个任务线程数)上面的数据可以看到,ES 写入线程数为 2 和 4 的时候区别不大,应该是 ES 线程数为 2 时整体耗时应该跟 MySQL 的读取耗时差不多。
总结与思考
多线程的方案思想和 MapReduce 很像,就是把一个大任务分割成若干小任务,最终汇总每个小任务的结果得到这个大任务的结果。这个思想与第一个单线程的方案相比,速度上肯定是无法比拟的。
这里还有一个问题,就是多个线程要保证完全高效利用:
-
比如,在上面 MySQL 数据的拆分时,肥壕是按照自增 id 来划分,所以理论上每个任务的任务量是一致的。
但是在测试库中,会有数据删除之类的操作,会出现划分不均匀的情况,所以这时每个线程分配的数据量就可能不太一样,导致个别线程会耗时比较长。
-
有的线程优先完成了任务,那能否帮助其他线程分摊一下任务?
了解过一下 Fork/Join 框架,貌似这个好像能解决上述的问题,等肥壕研究一番后再做讨论吧。
当然,如果有更好的提议和方案,非常欢迎多多指教!
普通的改变,将改变普通
我是宅小年,一个在互联网低调前行的小青年
关注公众号「宅小年」,个人博客 📖 edisonz.cn,阅读更多分享文章
