

Elasticsearch 作为主流的分布式搜索引擎,查询速度快,扩张性强,查询结果近实时。
也许有些小伙伴跟肥壕有同样的好奇,为什么查询结果是近实时的呢?
带着好奇心,让我们深入了解 Elasticsearch 的写入过程。
整体流程
我们知道每个索引 会被分成多个分片, 分片 又被分为主分片(primary shard)、副分片(replica shard)。增删改的操作都必先经过经过主分片,再同步到副分片。
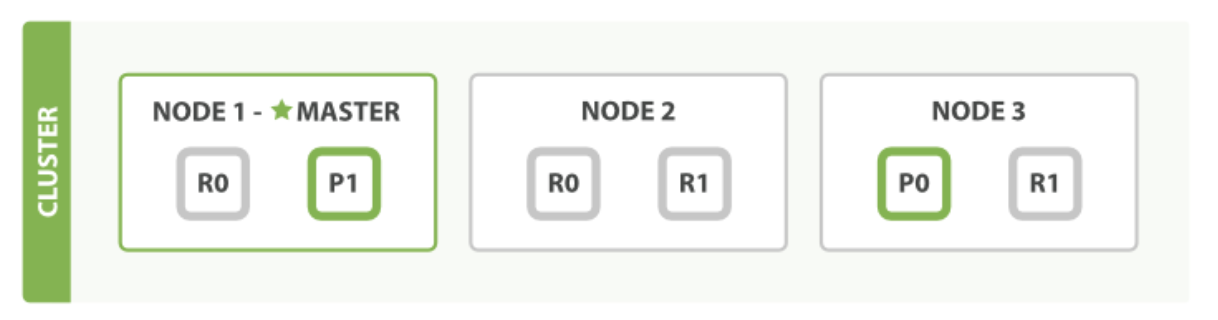
当有数据写入的时候,首先请求节点会根据 _routing路由规则找到对应的 primary shard,并将请求转发给 primary shard 所在的节点。primary shard 完成写入后,将写入并发发送给各 replica, raplica 执行写入操作后返回给 primary shard , primary shard 再将请求返回给请求节点。
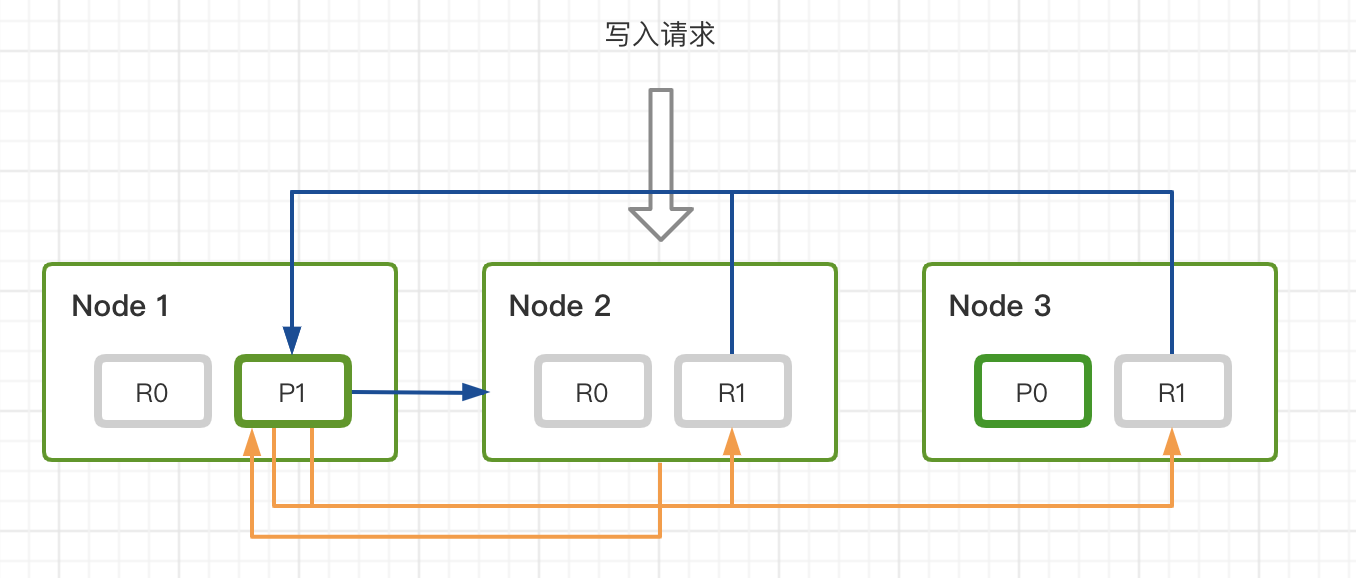
流程实现
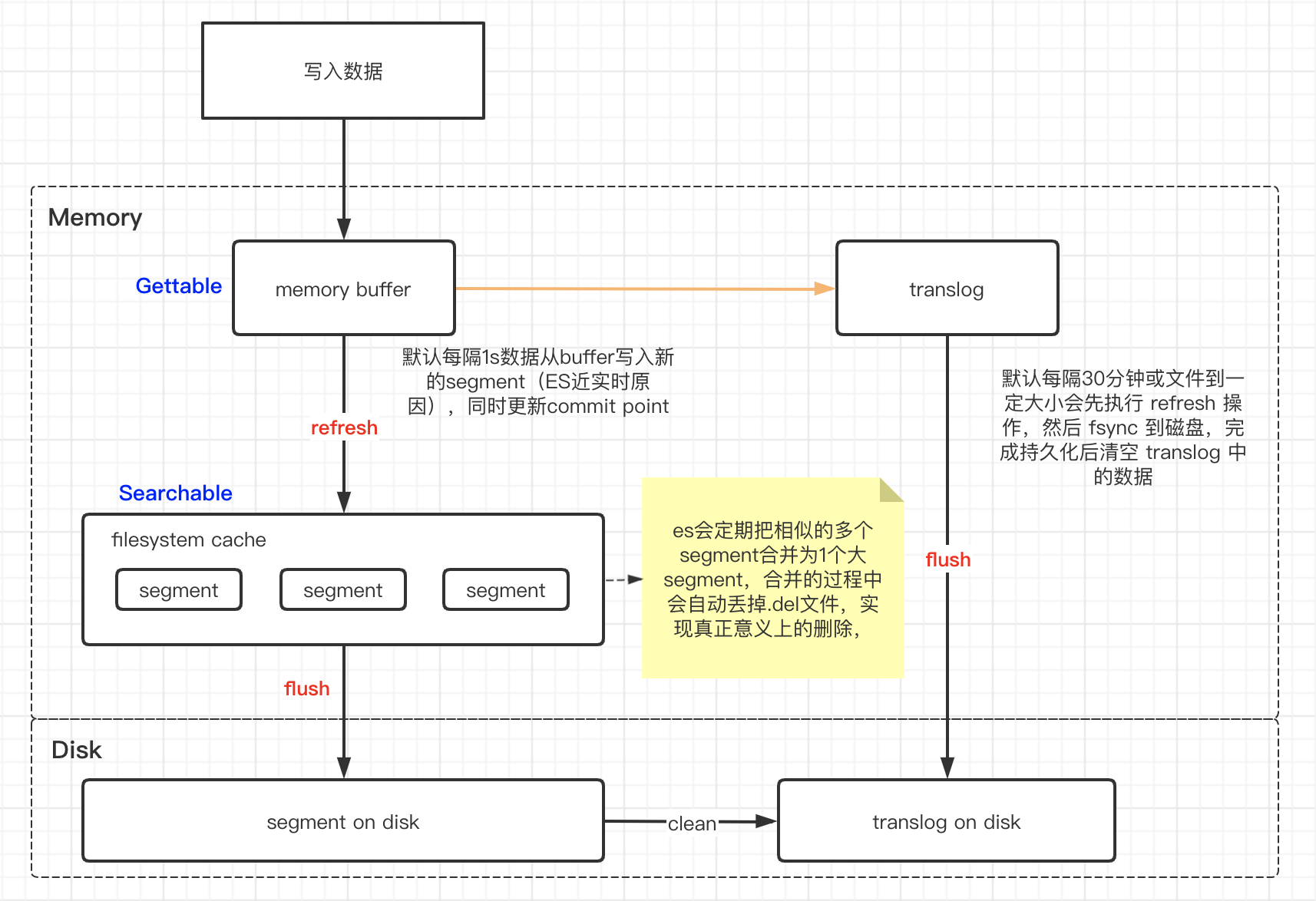
分段(Segment)
每个分片包含多个 segment(段),每一个 segment 都是一个倒排索引。在查询的时,会把所有的 segment 查询结果汇总归并后最为最终的分片查询结果返回。
commit point
记录当前所有可用的 segment,每个 commit point 都会维护一个.del 文件(ES 删除数据本质是不属于物理删除),当 ES 做删改操作时首先会在 .del 文件中声明某个 document 已经被删除,文件内记录了在某个 segment 内某个文档已经被删除,当查询请求过来时在 segment 中被删除的文件是能够查出来的,但是当返回结果时会根据 commit point 维护的那个 .del 文件把已经删除的文档过滤掉。
translog 日志文件
假如在写入数据的时候,ES 节点突然宕机,因为数据是先写入缓存中,所以可能会造成数据丢失的情况。为了保证数据存储的可靠性,ES 在写入缓存后,再写入 translog 日志文件,因为有可能缓存写入失败,为了减少写入失败回滚的复杂度,因此先写入缓存。由于 translog 是追加写入,因此性能要比随机写入要好。
refresh
ES 默认每隔 1 秒会从内存 buffer 中的数据写入 filesystem cache,这个过程叫做 refresh。这也是为什么说 ES 是近实时搜索的原因,因为数据写入到 filesystem cache 后才会被搜索到。
merge 操作
refresh 的过程会产生大量的小 segment,因此 ES 会有专门的任务检测当前磁盘中的 segment,对符合条件的 segment 进行合并操作,减少 lucene 中的 segment 个数,提高查询速度。不仅如此,merge 过程也是文档删除和更新操作后,旧的 doc 真正被删除的时候。用户还可以手动调用 _forcemerge API 来主动触发 merge,以减少集群的 segment 个数和清理已删除或更新的文档。
flush
每 30 分钟或当 translog 达到一定大小(由index.translog.flush_threshold_size控制,默认 512 mb ),ES 会触发一次 flush 操作,此时 ES 会先执行 refresh 操作将 buffer 中的数据生成 segment,然后调用 lucene 的 commit 方法将所有内存中的 segment fsync 到磁盘。此时 lucene 中的数据就完成了持久化,会清空 translog 中的数据
总结
- Elasticsearch 任意节点都可以作为协调节点,当接收到请求的的时候,会根据
_routing路由规则找到对应的主分片节点 - memory buffer 到 filesystem cache 之间的 refresh 操作是 Elasticsearch 近实时查询的原因。
- 通过引入 translog,定期的 flush、merge 保证了数据的可靠性和高效的存储性能
参考资料:
普通的改变,将改变普通
我是宅小年,一个在互联网低调前行的小青年
关注公众号「宅小年」,个人博客 📖 edisonz.cn,阅读更多分享文章
