

前言
今天的主题是:Apollo,分布式配置中心。
至于配置中心是什么,没接触过或者不熟悉的小伙伴可以自行先去了解一下。
在平时的项目开发中,比较常用的配置中心有:
- Apollo:携程开源的,并且具备规范的权限、流程治理等特性。
- Nacos:阿里开源的,功能集成丰富,可以做DNS和RPC的服务发现。
- Spring Cloud Config:Spring Cloud 生态组件,与 Spring Cloud 体系无缝整合。
Apollo 目前在国内的开发者社区热度还是比较高的,在Github 上已经有10w ⭐,已经有很多互联网公司成熟的落地案例。当然,后起之秀的 Nacos 同样也是一个很不错的配置中心框架。
关于这三个的优缺对比,网上也有很多资料,大家一搜便是。
介于之前在项目上借鉴了 apollo 的一些设计和实现,也看了一些源码,而本期的重点主要是想分享一下 apollo 的一些个人觉得比较核心和有意思的技术点,所以有关其他的配置中心这里就不展讲。
但是要记住一句:没有最好的,只有最合适的。要结合项目的实际业务场景,选择最合适的,才会有实践的价值。
正文
整体架构
其实配置中心的整体设计和实现思路大多数都是大同小异,知其一,可推其二。
比如说,下图中的用例模型。对于其他的配置中心框架,也是类似的。
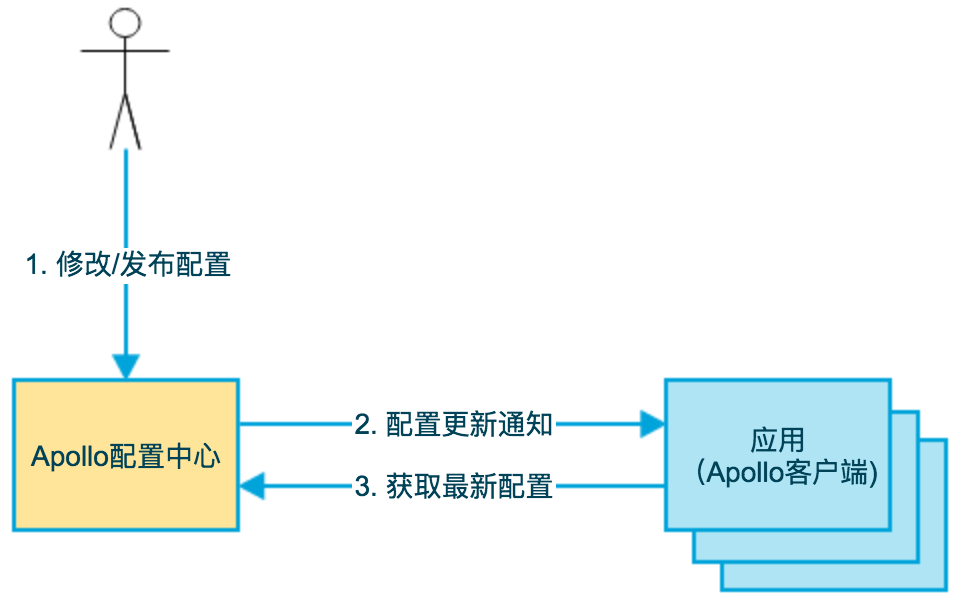
- 用户在配置中心对配置进行修改并发布
- 配置中心通知Apollo客户端有配置更新
- Apollo客户端从配置中心拉取最新的配置、更新本地配置并通知到应用
Http Long Polling(长轮询)
Apollo 配置中心与应用之间的配置更新通知,是通过 Http Long Polling 实现的。
Http Long Polling(长轮询),是什么?
对于初学者来说, 听起来似乎是个什么高大上的技术。但其实它的原理很简单,客户端发起 http 请求,此时如果服务端没有数据返回,就会 hold 这个请求,直到有数据过来或者是等到接口的超时时间,才会返回这个请求。
简单来说,它也就是一次http请求,只不过是由服务端来控制响应的时间和结果。
如果说到实效性,那有人可能会问:为什么不用 websocket 呢?
没错,如果是使用 websocket ,客户端与服务端之间的消息同步确实会更及时,而且对比于 Htto Long Polling 来说,也不需要维护长轮询连接,对服务器的资源消耗更小。
既然 Apollo 选用长轮询的方式来实现两端之间的数据同步,一定是有它的道理。具体问题,还得要结合具体的业务场景分析。
我的看法是,本身应用配置的修改不会很频繁,而且配置属性值也不会很大。第二个是websocket 实现起来比较重,也比较复杂,应用依赖的客户端SDK目的也是尽可能的轻便,而长轮询在客户端的实现上跟发起一个http请求一样简单。
长轮询的实现
Spring 提供 DeferredResult 实现服务端的长轮询,apollo 的源码中也是使用 DeferredResult 来实现的。
异步支持是在 Servlet 3.0 中引入的,简单地说,它允许在另一个线程而不是请求接收线程中处理HTTP请求。
DeferredResult 从 Spring 3.2 开始提供,它可以帮助将一个长时间运行的计算从 http 工作线程交给到一个单独的线程。
尽管另一个线程将占用一些资源进行计算,但工作线程在此期间不会阻塞,并能够处理传入的客户端请求。异步请求处理模型非常有用,因为它有助于在高负载时很好地扩展应用程序,特别是对于 IO 密集型操作。
Apollo 服务端源码的逻辑稍微有点复杂,我们先看下面的简单的示例代码:
// guava中的Multimap,一个key可以保持多个value
private final Multimap<String, DeferredResult<String>> deferredResultMap = HashMultimap.create();
// 超时时间 10s
private long DEFAULT_LONG_POLLING_TIMEOUT = 10 * 1000;
/**
* 模拟监听namespace配置
*/
@GetMapping("/listen")
public DeferredResult<String> pollNotification(@RequestParam("namespace") String namespace) {
// 创建DeferredResult对象,设置超时时间和超时返回对象
DeferredResult<String> result = new DeferredResult<>(DEFAULT_LONG_POLLING_TIMEOUT, "timeout");
result.onTimeout(() -> log.info("timeout"));
result.onCompletion(() -> {
log.info("completion");
deferredResultMap.remove(namespace, result);
});
deferredResultMap.put(namespace, result);
return result;
}
/**
* 模拟发布namespace配置
*/
@GetMapping(value = "/publish")
public Object publishConfig(@RequestParam("namespace") String namespace, @RequestParam("context") String context) {
if (deferredResultMap.containsKey(namespace)) {
Collection<DeferredResult<String>> deferredResults = deferredResultMap.get(namespace);
for (DeferredResult<String> deferredResult : deferredResults) {
deferredResult.setResult(context);
}
}
return "success";
}
首先,我们肯定会维护一个全局的 deferredResultMap 哈希表记录所有长轮询的请求,例子中我们是采用 namespace 做为key。
请求 /listen 接口,相当于模拟应用长轮询 Apollo 配置中心的场景,监听配置变更的通知。
然后再调用提供的一个模拟发布配置的接口,触发 DeferredResult 的 setResult() 方法,就相当于唤醒异步任务线程,返回结果。
当异步线程完成任务或者超时,都会回调 onCompletion() 方法,所以我们在这个方法中把全局哈希表清除当前这个请求记录。
总的来说,实现起来还是比较简单的。
注意超时时间的设置
虽然说超时时间是由服务端控制,但是在真正的项目环境中,要注意是否有接入网关、限流组件,比如 nginx 它的默认超时就是60s,如果你的服务端设置的超时时间大于60s,可能网关就直接给你关闭这个链接了。
如何保证消息不丢失
这里说的消息不丢失,是指 Apollo 配置中心通知应用配置变更的消息。
Apollo 客户端多节点部署,假设用户在后台修改了配置,Apollo 服务端会通知到客户端,而此时有一个客户端节点 A 刚好出现网络异常,没收到通知,那么这个节点 A 的配置就跟集群中其他节点的配置产生数据不一致的问题。
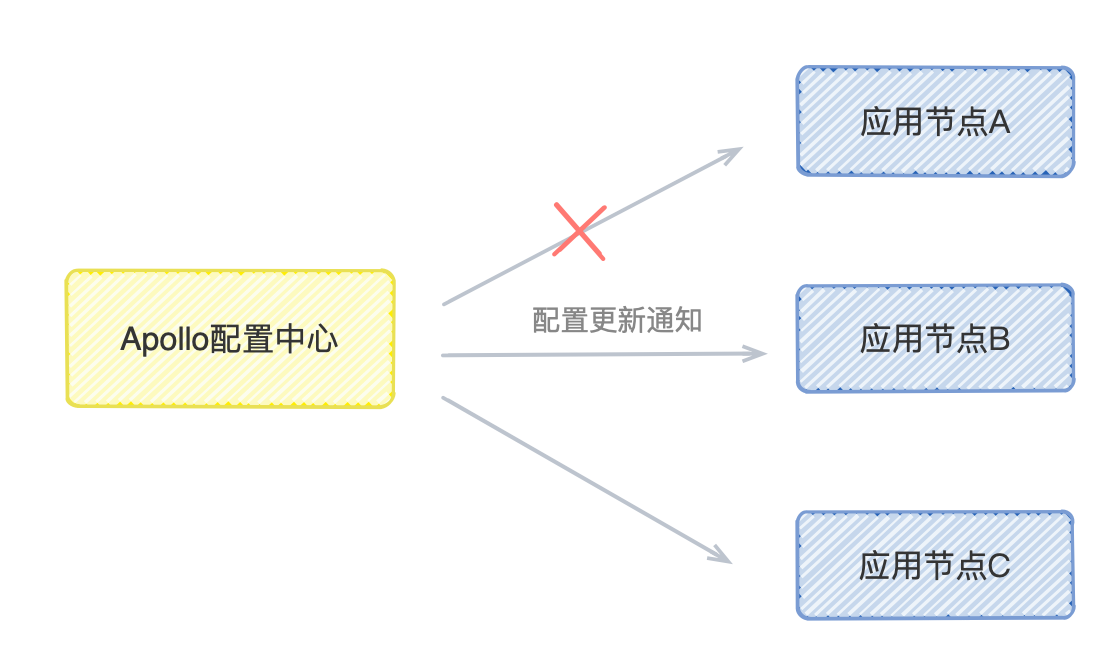
当然,如果你的系统对这个配置没有特别高要求实效性的话,这个这个问题就不是问题了,apollo 客户端有一个5min的兜底机制,也就是说异常点节点最多晚 5min 才会同步这个最新的配置。
但如果你的业务是依赖这个配置,比如说某个业务流程的设置,或者是灰度的控制开关等,那就有可能会造成系统异常。
对于这个问题,Apollo 当然有相应的解决方案。但在分享解决方案之前,如果是你碰到这个问题,你会怎么解决呢?
其实,只要认真思考一下,办法总是有的。我们的问题是,客户端节点A因为网络异常,导致长轮询接口断开,丢失了配置变更通知的消息,产生数据不一致。换句话说,我们需要解决的是:客户端节点 A 当恢复网络后,与服务端的长轮询接口正常通讯时,要获取到之前丢失的消息。
要知道,apollo 服务端所有配置的更改记录都会持久化到数据库中。那么就意味着,这条丢失的配置变更消息,其实是可以通过数据库查询得到的。
那么 apollo 是怎么实现的呢?
其实原理非常简单,每一条存储到数据库中的更改记录都有对应的一个 notificationId(自增主键),客户端每次的长轮询,服务端都会返回当前配置变更内容和 notificationId,而请参则会带上上一次获取到的 notificationId。服务端在返回的时候根据客户端带上的 notificationId 查询下一条消息。
看这原理,是不是有点分页查询的 lastId 的内味。
看到 RemoteConfigLongPollService 中的 doLongPollingRefresh方法,客户端长轮询的实现:
private void doLongPollingRefresh(String appId, String cluster, String dataCenter, String secret) {
final Random random = new Random();
ServiceDTO lastServiceDto = null;
while (!m_longPollingStopped.get() && !Thread.currentThread().isInterrupted()) {
// 省略
.......
try {
// 1.随机获取一个服务端的配置DTO
if (lastServiceDto == null) {
List<ServiceDTO> configServices = getConfigServices();
lastServiceDto = configServices.get(random.nextInt(configServices.size()));
}
// 2.封装请求apollo服务端的url和参数(包括 notificationId)
url = assembleLongPollRefreshUrl(lastServiceDto.getHomepageUrl(), appId, cluster, dataCenter,
m_notifications);
logger.debug("Long polling from {}", url);
HttpRequest request = new HttpRequest(url);
request.setReadTimeout(LONG_POLLING_READ_TIMEOUT);
if (!StringUtils.isBlank(secret)) {
Map<String, String> headers = Signature.buildHttpHeaders(url, appId, secret);
request.setHeaders(headers);
}
transaction.addData("Url", url);
final HttpResponse<List<ApolloConfigNotification>> response =
m_httpClient.doGet(request, m_responseType);
logger.debug("Long polling response: {}, url: {}", response.getStatusCode(), url);
if (response.getStatusCode() == 200 && response.getBody() != null) {
// 3.更新notificationId
updateNotifications(response.getBody());
updateRemoteNotifications(response.getBody());
transaction.addData("Result", response.getBody().toString());
notify(lastServiceDto, response.getBody());
}
// 省略
.......
}
}
在注释的步骤2 中,方法 assembleLongPollRefreshUrl 会把上一次获取到的 notificationId 作为长轮询接口的参数。
总结
本篇主要分享了 Apollo 的一个比较核心的技术,长轮询(Http Long Polling),虽然说这并不是一个非常硬核或者是含金量非常高的技术,但是技术本身就是为业务而服务的,能够实现业务价值的就是好技术。而它也确确实实的能够提供提供一个成熟和可靠的分布式配置中心方案。
同时,也分享了在一些网络异常等异常的情况下,如何保证多节点之间配置通知的可靠性。
当然,源码上的实现会比上面的更加复杂一些,而且在配置变更的实现上,Apollo 使用了类似发布订阅的设计模式,有兴趣的同学不妨可以阅读一下。
参考
https://www.apolloconfig.com/#/zh/design/apollo-design
普通的改变,将改变普通
我是宅小年,一个在互联网低调前行的小青年
关注公众号「宅小年」,个人博客 📖 edisonz.cn,阅读更多分享文章
