

前言
大家都知道,RocketMQ 消息每次的发送与接收,实际上都是对磁盘数据的写入与读取,而磁盘 I/O 性能的瓶颈是比较低的,那么它又是如何提供百万消息的高性能读写的呢?
现在很多主流的消息中间件比如 Kafka、RocketMQ,它们能做到百万消息的高性能读写,其实背后都少不了零拷贝的实现。
那可能有人会问:这个零拷贝究竟是什么黑魔法?
其实,零拷贝已经是一道老生常谈的面试题,可能大多数人也可能早已经知道这其中的原理,资料上网一搜便也琳琅满目。
那么本篇跟随小年的步伐一同探讨 RocketMQ 的高性能秘诀。
正文
传统文件 IO
Linux 分为用户空间和内核空间,应用程序运行在用户空间,操作系统和驱动程序运行在内核空间,应用程序要读取磁盘等硬件设备,必须要先经过内核空间的中转处理,用户空间是无法直接访问到硬件层的。
因此对于传统 IO 的工作流程,数据读取和写入都必须经过用户空间和内核空间的多次复制。
假设有这么一个场景:服务端的一个应用程序需要读取磁盘文件的数据,发送给网络另一头的客户端。
传统 IO 场景下数据传输的链路:
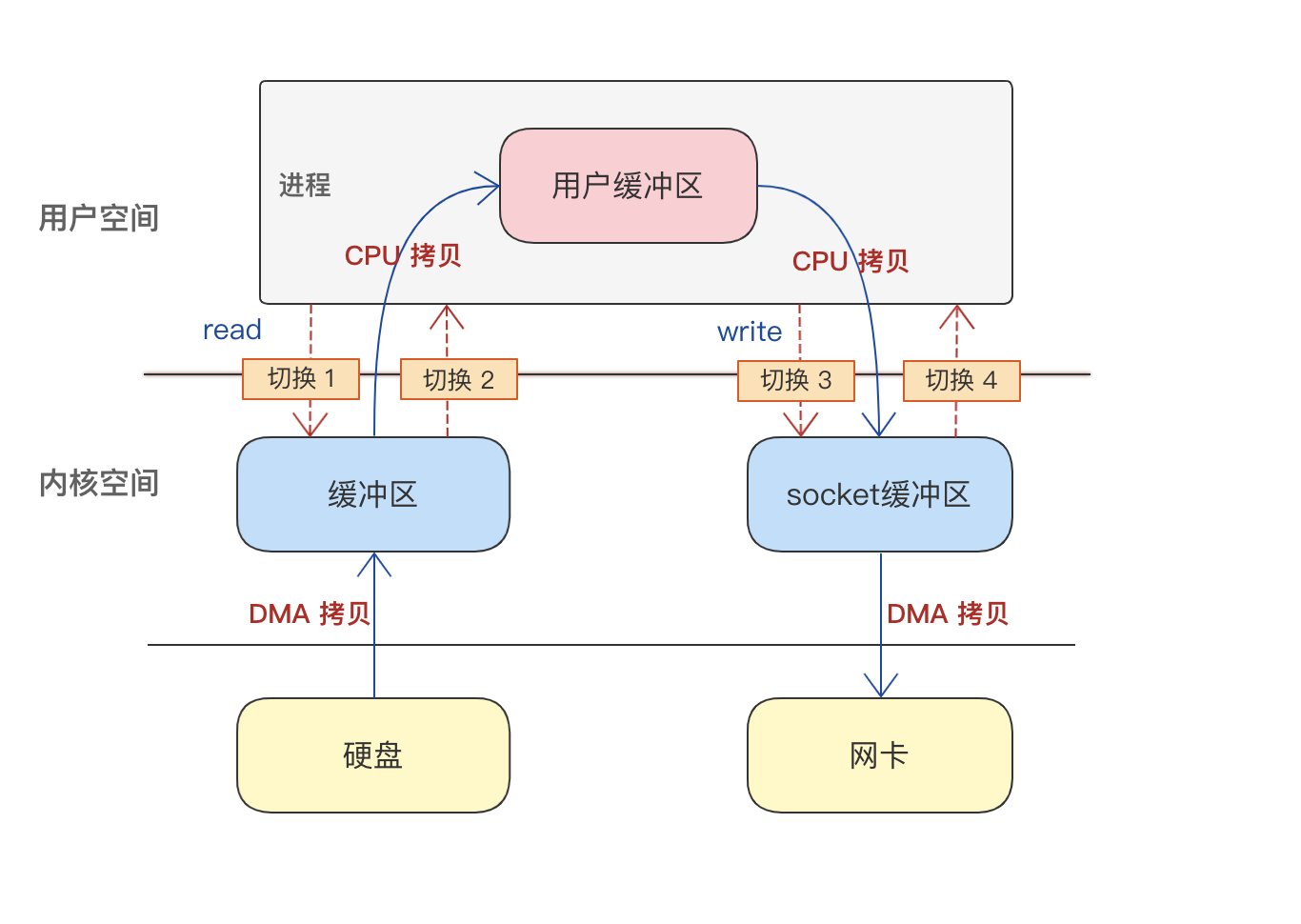
可以看到,这里的重点是在这个过程发生了 4 次上下文切换、 4 次数据拷贝
因为发生了两次的系统调用,一次是 read() 、一次是 write(),每次系统调用都先从用户态切为内核态,等内核态完成任务后,再从内核态切为用户态。
这会可能就有同学会有疑问:DMA 拷贝又是什么?
DMA(Direct Memory Access) 直接内存访问
简单理解就是,在 I/O 设备和内存进行数据传输的时候,数据传输的工作全部交由 DMA 控制器负责,而 CPU 这时候就可以抽身去处理别的事务。
我们先来看一下使用 DMA 技术之前:
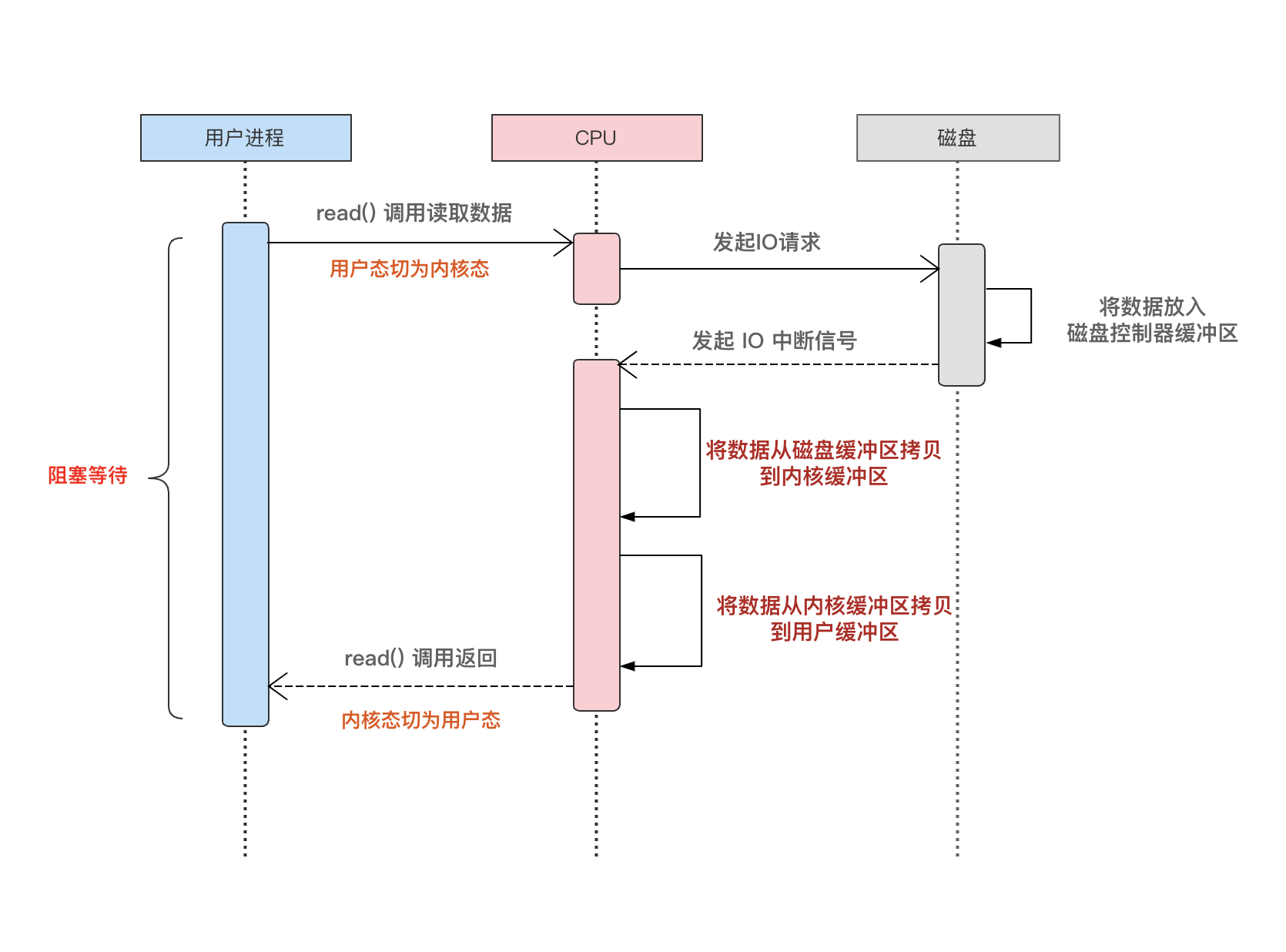
从上面的图可以看到,CPU 要参与整个数据读取、搬运的整个生命周期,而且在磁盘读取数据的过程中,CPU 是阻塞的,不能做其他任何的事情。
为了解决这个问题,于是就诞生了 DMA 技术。
再来看看使用 DMA 技术后:
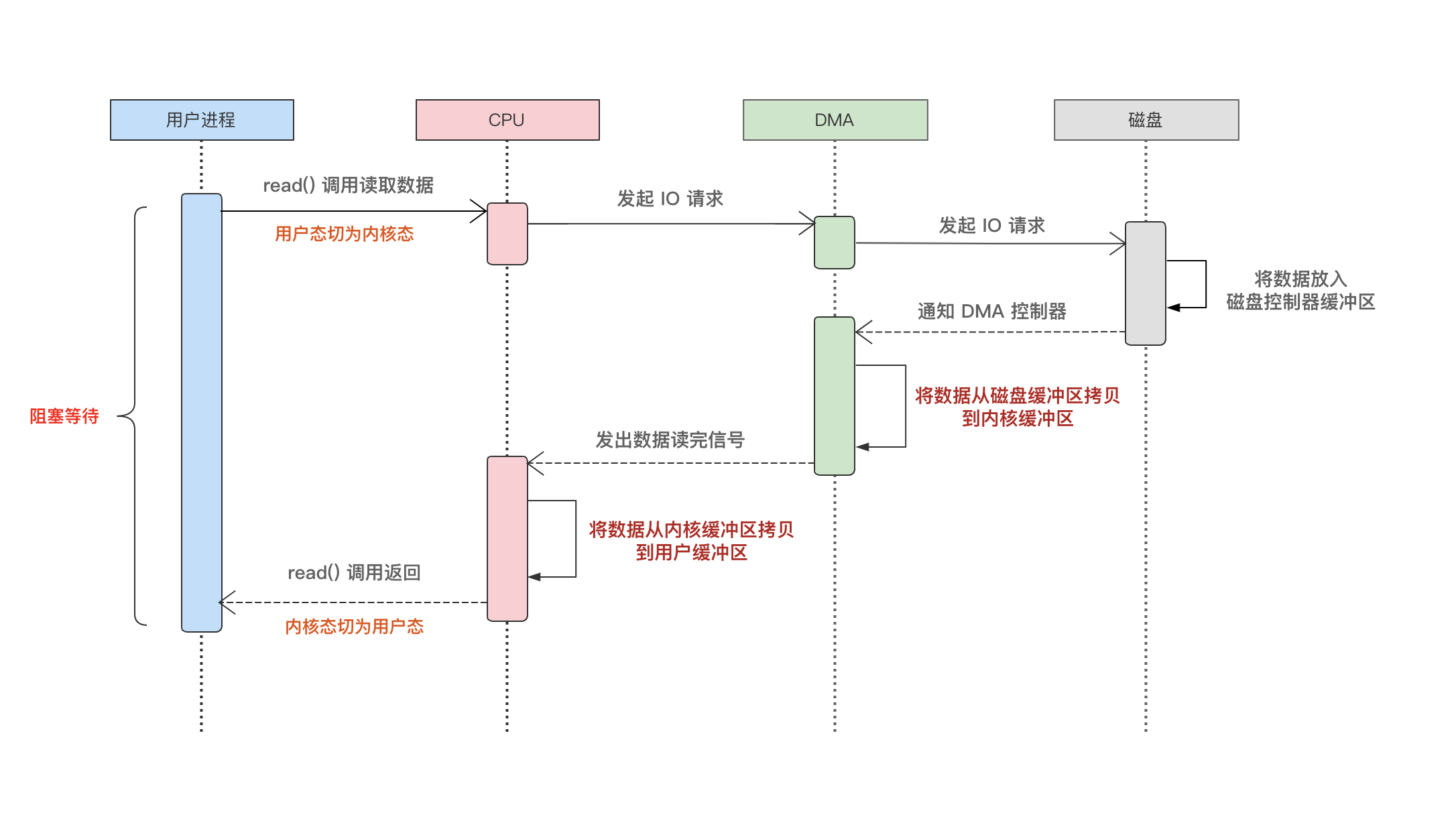
在磁盘和 CPU 之间增加一个 DMA,负责磁盘数据搬运的工作。很显然,这种方案对比于上面的来说,释放了 CPU 在磁盘数据搬运的阻塞等待,这时 CPU 可以解放双手做其他的事情了!
所以 DMA 技术也是实现 零拷贝 必不可少的一个角色。
思考
再回顾传统 IO 读写的整个流程过,我们知道一次文件的读写需要
- 4 次上下文切换
- 4 次数据拷贝
但如果我们再仔细想想,其实这里的用户空间与内核空间之间的数据拷贝和上下文切换是不是可以有更进一步的优化?
因为这个过程中用户空间只是扮演一个搬运的角色。
所以,如果能够减少用户空间这一层繁琐的数据拷贝和上下文切换,由应用京城调用后,数据直接在内核空间从磁盘搬运到网卡,这样是不是性能更进一步提升?
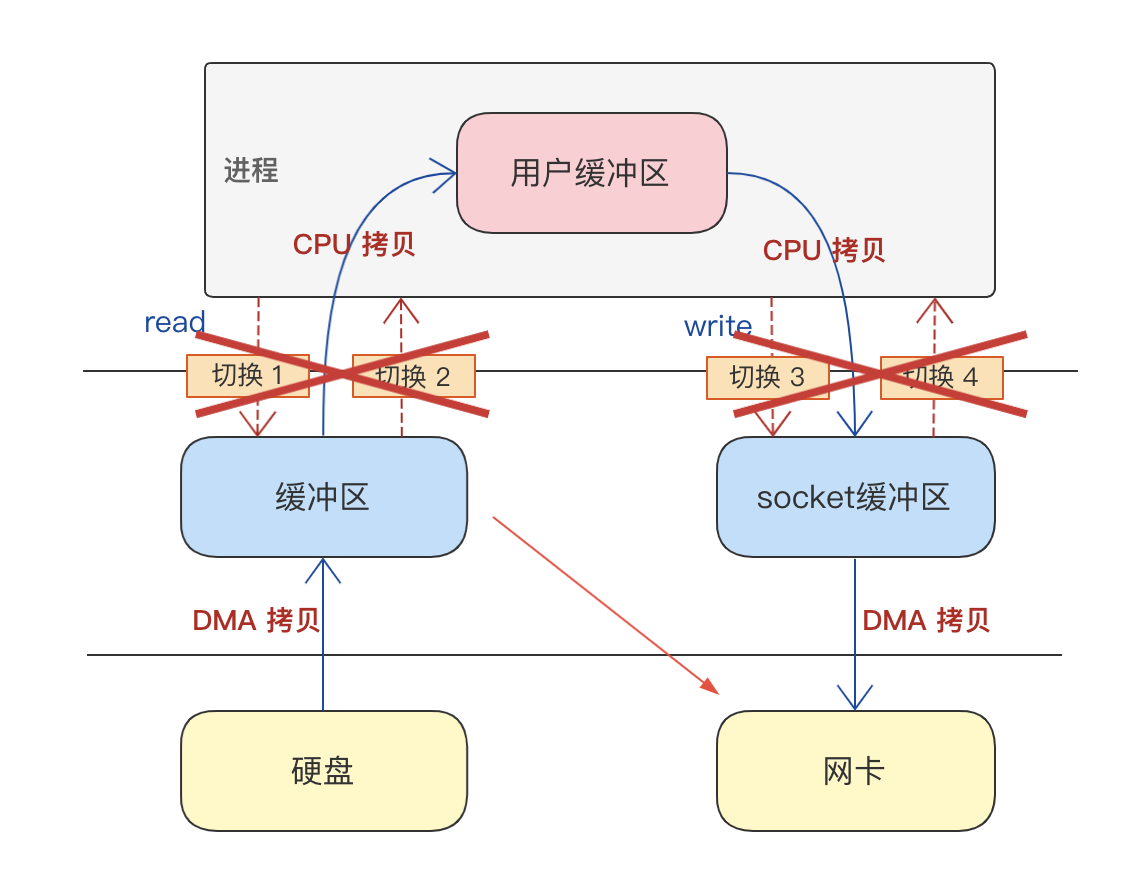
零拷贝,因此应运而生。
零拷贝
而实现零拷贝主要是这两个主角:
- mmap
- page cache
MMAP
mmap() creates a new mapping in the virtual address space of the calling process. The starting address for the new mapping is specified in addr. The length argument specifies the length of the mapping (which must be greater than 0).
简而言之,内存映射,就是将磁盘文件映射到用户空间的一段内存区域中,用户进程可以直接操作这段虚拟地址进行文件的读写等操作,系统都会自动会回写到对应的文件磁盘上。
调用 mmap 进行内存映射时,操作系统其实只是建立虚拟内存地址至物理地址的映射表,而实际并没有加载任何文件至内存中,只有当真正读写这段数据的时候,在 MMU 地址映射表中找不到逻辑指针对应的物理地址的时候,会发生缺页中断,将文件加载到内存。
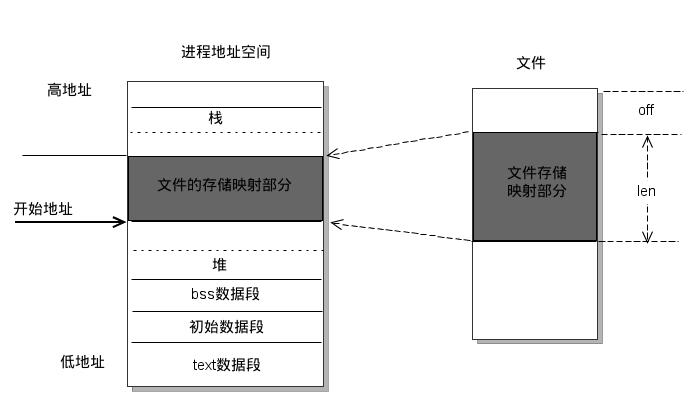
mmap 与 read、write 都是 unix/linux 下的指令函数,但是与之相比 mmap 通过内存直接操作磁盘文件,减少了用户空间与内核空间之间的一次数据拷贝。
那么问题又来了,解决了用户态与内核态之间的数据传输,但是在内核缓冲到socket缓冲区之间还存在数据拷贝。
- 在 Linux 内核版本 2.1 中,提供了一个专门发送文件的系统调用函数
sendfile(),它可以替代前面的read()和write()这两个系统调用,这样就可以减少一次系统调用,也就减少了 2 次上下文切换的开销。 - 从 Linux 内核
2.4版本开始起,对于网卡支持 SG-DMA 技术的情况下,网卡的 SG-DMA 控制器就可以直接将内核缓存中的数据拷贝到网卡的缓冲区里,此过程不需要将数据从操作系统内核缓冲区拷贝到 socket 缓冲区中,这样就减少了一次数据拷贝。
显而易见,零拷贝技术与传统文件传输的方式相比,那是提升了一个质的飞跃呀。原本需要 4 次上下文的切换、4 次数据拷贝,现在 2 次上下文的切换和数据拷贝。
由于 Linux 的内存页机制,内存分配的最小粒度是页,而进程虚拟地址空间和内存的映射也是以页为单位。因此 mmap 映射区域大小必须是物理页大小的整倍数(通常是4k字节)。
RocketMQ中 的 CommitLog 文件大小默认设置为1G
// CommitLog file size,default is 1G
private int mapedFileSizeCommitLog = 1024 * 1024 * 1024;
Java中的 MappedByteBuffer 便是对应 mmap 实现,在Java中一次只能映射1.5~2G 的文件内存。
RocketMQ 中的 MappedFile 源码示例:
private void init(final String fileName, final int fileSize) throws IOException {
this.fileName = fileName;
this.fileSize = fileSize;
this.file = new File(fileName);
this.fileFromOffset = Long.parseLong(this.file.getName());
boolean ok = false;
ensureDirOK(this.file.getParent());
try {
this.fileChannel = new RandomAccessFile(this.file, "rw").getChannel();
this.mappedByteBuffer = this.fileChannel.map(MapMode.READ_WRITE, 0, fileSize);
TOTAL_MAPPED_VIRTUAL_MEMORY.addAndGet(fileSize);
TOTAL_MAPPED_FILES.incrementAndGet();
ok = true;
} catch (FileNotFoundException e) {
log.error("create file channel " + this.fileName + " Failed. ", e);
throw e;
} catch (IOException e) {
log.error("map file " + this.fileName + " Failed. ", e);
throw e;
} finally {
if (!ok && this.fileChannel != null) {
this.fileChannel.close();
}
}
}
Page Cache
这里就要介绍另一位魔法师,Page cache。
上面说过,Rocketmq 中 broker 所有的消息都是需要落盘的,而我们也知道磁盘的 IO 性能是非常低效的。
Linux 为了提高磁盘的读写速度,加快对磁盘文件数据的访问,利用物理内存来缓存磁盘文件的逻辑内容,而这个就叫 Page Cache。像上面介绍 DMA 中的「磁盘缓冲区」指的就是 PageCache。
Page cache 也叫页缓冲或文件缓冲,是由好几个磁盘块构成,大小通常为 4 K,在 64 位系统上为 8 k,构成的几个磁盘块在物理磁盘上不一定连续,文件的组织单位为一页, 也就是一个 page cache 大小,文件读取是由外存上不连续的几个磁盘块,到 buffer cache,然后组成 page cache,然后供给应用程序。
简单来说,应用程序进程不再直接操作磁盘IO,而只需要往内存缓存区写数据,数据的落盘操作就交给系统了。
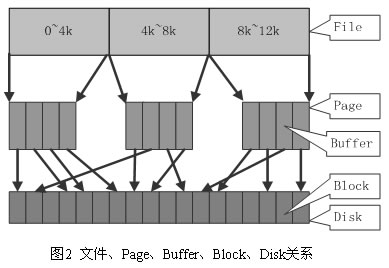
所以这里其实在物理磁盘与 Page Cache 还有一层 Buffer Cache 。
Buffer cache 块缓冲,是对物理磁盘上的一个磁盘块进行的缓冲,其大小为通常为1k,磁盘块也是磁盘的组织单位。设立 buffer cache 的目的是为在程序多次访问同一磁盘块时,减少访问时间
简单总结一下,page cache 用来缓存文件数据,buffer cache 用来缓存磁盘数据。在有文件系统的情况下,对文件操作,那么数据会缓存到 page cache,如果直接采用 dd 等工具对磁盘进行读写,那么数据会缓存到 buffer cache。
在终端输入命令: free -m

这里的 「buff / cache」就是指我们所说的 buffer cache 和 page cache了。
Page cache 还有一个特性,预读
所谓的预读,其实也很好理解。应用程序当前可能只读取一小部分数据,但文件系统会提前为应用程序读取更多数据到缓存到page chache中,这样下一次读取的时候可以直接命中page cache。
比如用户线程当前读取文件是 4KB 的数据,内核的预读算法则会以它认为更合适的大小进行预读 I/O,比如16-128KB,然后一并缓存到 page cache。
对于现在常见的机械硬盘来说,一般都是通过扇区顺序读写的。如果能够预先将用户下次需要读取的数据提前缓存到 page cache,这样可以有效的减少磁盘的寻道次数和应用程序的 I/O 等待时间。
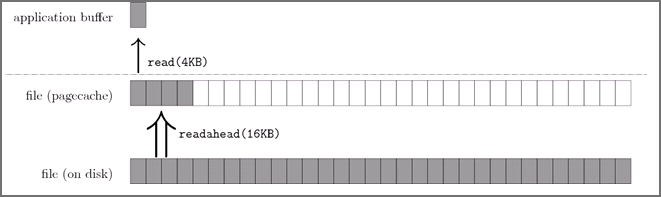
当然,预读的作用还是取决于文件的访问是随机的还是连续的,如果是连续访问,那自然就能发挥预读的效果,大大提高访问性能;如果是随机访问,那么就可能适得其反,甚至造成内存的浪费和占用 I/O 带宽。
MMAP 和 Page Cache 并非银弹
当然,mmap 和 pageCache 也不是说万能的,什么场景都适用。
mmap 与 page cache 大小限制
-
不适合大文件
虽然说 mmap 在创建的时候只会创建虚拟内存,但是如果映射的文件过大,在读写的过程可能会导致占用过多的 page cache,以致于无法利用到 page cache 缓存热点数据和预读的特性。
-
不适合变长文件
mmap 使用时需要指定映射文件的大小,内存必须是内存页的整数倍(一般是4k)。
-
磁盘延迟
mmap 通过缺页中断向磁盘发起真正的磁盘 I/O,也就是说写入到内核缓存的数据,至于何时写入磁盘是交由系统负责。
RocketMQ 是如何基于 mmap + page cache 进行优化的?
(1)内存预映射机制
RocketMQ 消息写入对应的文件实现类是 MappedFile,上面也贴出了 MappedFile 创建和初始化的源码,这个过程其实也就是申请内存映射的过程。
RocketMQ 会维护一个 MappedFileQueue 队列,在每次消息的写入,会获取队列中最后一个 MappedFile,如果没有则会创建一个,并且把下一个也会创建出来。
这种策略便是 RocketMQ 预分配 MappedFile,也叫 内存预映射机制 。 它的思路很巧妙,能够在下次获取时候直接返回 MappedFile 实例而不用等待 MappedFile 创建分配所产生的时间延迟。
(2)文件预热
上面也提到过,调用 mmap 进行内存映射,其实只是建立虚拟内存地址至物理地址的映射关系,不会加载任何文件至内存中。
RocketMQ 在进行内存映射后,会预先写入数据到文件中,并且将文件内容加载到 page cache,当消息写入或者读取的时候,可以直接命中 page cache,避免多次缺页中断。
org.apache.rocketmq.store.MappedFile#warmMappedFile
public void warmMappedFile(FlushDiskType type, int pages) {
......
//每隔一个页(4k)put一个0,将文件加载到内存
for (int i = 0, j = 0; i < this.fileSize; i += MappedFile.OS_PAGE_SIZE, j++) {
byteBuffer.put(i, (byte) 0);
// force flush when flush disk type is sync
......
// prevent gc
if (j % 1000 == 0) {
log.info("j={}, costTime={}", j, System.currentTimeMillis() - time);
time = System.currentTimeMillis();
try {
// sleep(0)是为了让出时间片,让操作系统重新选择线程。
Thread.sleep(0);
} catch (InterruptedException e) {
log.error("Interrupted", e);
}
}
}
......
this.mlock();
}
这里可以看到 MappedByteBuffer每隔 4K 就写入一个 0 byte,然后将整个文件撑满,而 4K 恰好就是一个缓存页的大小。
(3)mlock内存锁定
上面可以看到,在MappedFile 预热后,会调用 mlock() 方法,而这个方法有什么作用呢?
我们先看一下方法里面的代码:
public void mlock() {
final long beginTime = System.currentTimeMillis();
final long address = ((DirectBuffer) (this.mappedByteBuffer)).address();
Pointer pointer = new Pointer(address);
{
int ret = LibC.INSTANCE.mlock(pointer, new NativeLong(this.fileSize));
log.info("mlock {} {} {} ret = {} time consuming = {}", address, this.fileName, this.fileSize, ret, System.currentTimeMillis() - beginTime);
}
{
int ret = LibC.INSTANCE.madvise(pointer, new NativeLong(this.fileSize), LibC.MADV_WILLNEED);
log.info("madvise {} {} {} ret = {} time consuming = {}", address, this.fileName, this.fileSize, ret, System.currentTimeMillis() - beginTime);
}
}
该方法主要是实现文件预热后,防止把预热过的文件被操作系统调到swap空间中。当程序在次读取交换出去的数据的时候会产生缺页异常。
- LibC.INSTANCE.mlock:将锁住指定的内存区域避免被操作系统调到swap空间中。
- LibC.INSTANCE.madvise:一次性先将一段数据读入到映射内存区域,可以减少了缺页异常的产生。
总结
零拷贝,是作为程序员进阶必须掌握的知识点。在掌握基本的理论知识的同时,我们也需要结合实践,通过深入具体的实现代码、落地场景,才能更加融会贯通,理解到位。
而本篇通过 RocketMQ 为引例,认识到它是如何通过零拷贝,实现高效的读写性能。
而且不仅是 RocketMQ,目前市面上主流的消息中间件,Kafaka、RabbitMQ 等大多数都是基于零拷贝的技术实现的。
但当然零拷贝也并非是银弹,它也并不是适合所有的场景,具体的场景要具体分析。
希望本篇文章能让你受益良多,如有不足之处,随时欢迎评论。