

小年最近在做支付相关的项目。在支付场景中,尤其是涉及金额交易的,不仅需要较高的安全性,而且对数据的一致性也有一定的要求。
业务系统按照微服务架构拆分之后,一个完整的业务链路可能需要涉及调用多个微服务,如何保证多个服务间的数据一致性成为一个难题。

分布式事务是一个比较复杂问题,业界上也有很多解决方案。如果对分布式事务有过了解的同学,相信都听说过 Seata 。
Seata 是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务。
但官网上的介绍,对于像小年这种新手菜鸟来说并不容易理解,所以结合一些资料,通过更加通俗易懂的方式呈现出来。
Seata 有 4 种模式,而本篇的主题是聊一聊:Seata 分布式事务中的 AT 模式。
业务流程
AT 模式是一种无侵入的分布式事务解决方案。在 AT 模式下,用户只需关注自己的“业务 SQL”,用户的 “业务 SQL” 作为一阶段,Seata 框架会自动生成事务的二阶段提交和回滚操作。
老规矩,我们还是先从例子来上手。
参考官网中用户购买商品下单的用例,用户发起支付下单,扣减库存,再扣减用户余额。
整个业务逻辑由 4 个微服务提供支持:
- 业务服务:业务入口,处理业务逻辑
- 库存服务:扣减商品的库存数量
- 订单服务:创建支付订单
- 帐户服务:扣减用户账户的余额
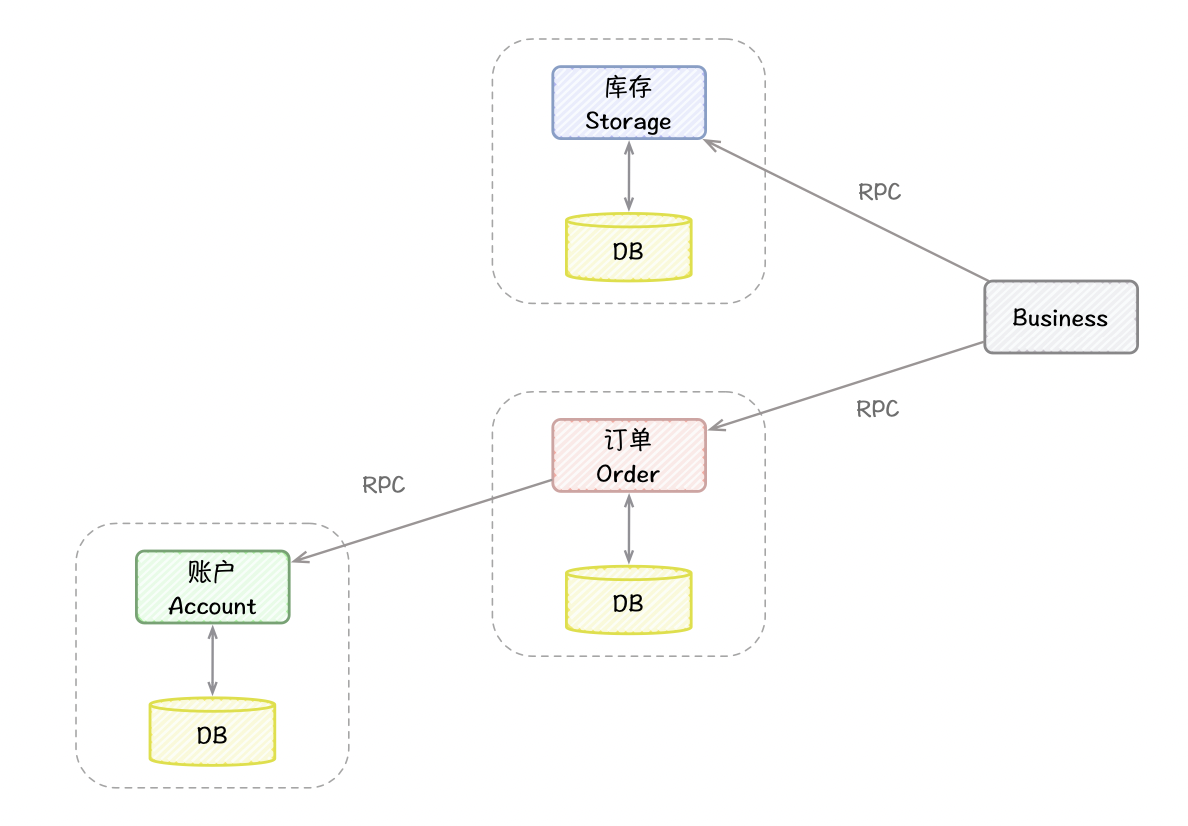
我们来看一下,在用户购买商品的过程中,发生了哪些数据的变化:
- 扣减商品库存
- 创建支付订单
- 扣减账户余额
这三次的数据变更操作,严格来说,都应该要遵循数据一致性。即如果创建支付订单失败或者扣减账户余额失败,商品库存扣减也应该要一随回滚撤销。
对于已往的单体应用中,我们是可以依靠本地事务来实现这三个表数据的一致性,但是拆分为微服务体系架构后,库存、订单、账户三个微服务,都维护各自领域的数据库,那么事务就不再管用了。

在了解 AT 模式之前,我们不妨自己思考一下:要怎么解决上述场景中的分布式事务?
首先,目的要清楚知道,这三个事务操作从全局来看是属于一个整体事务,只要其中任何一个服务的事务失败了,其他两个服务也要跟着回滚。
然后,我们的问题就可以再细分到,其他的服务如何感知当前执行的这个事务执行失败了呢?
消息通知?又或者是有一个类似于管理中心的角色来做统一管理?
当你想到这一步的时候,其实你其实已经差不多入门 AT 模式了。
下面让我们在 AT 模式下,是怎么解决这个问题的。
先来介绍一下 3 个核心组件:
- 事务协调器(TC):Transaction Coordinator,监视每个全局事务的状态,负责全局事务的提交和回滚。
- 事务管理者(TM):Transaction Manager,向TC发起,提交,回滚全局事务的请求。
- 资源管理器(RM):Resource Manager,服务向TC发起,提交,报告分支事务的请求,并且服务本地事务的回滚,提交。
光看这几个概念可能不太好理解,我们继续用上面的例子结合 AT 模式👇
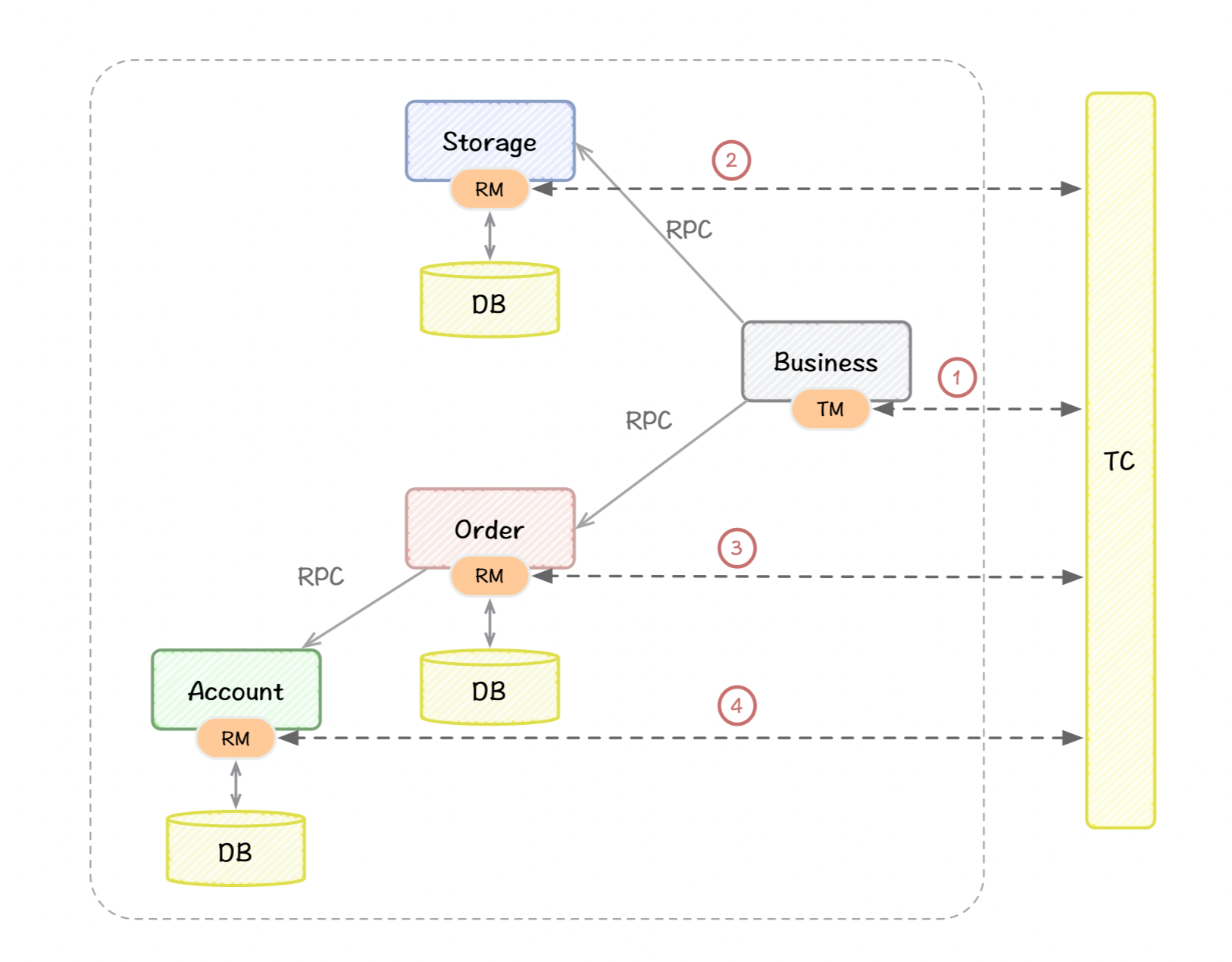
可以看到与之前的图相比,在最右侧多了一个事务协调器(TC),这是一个独立运行的服务,主要的作用是管理和协调各个微服务的事务。
Business 是整个业务的入口(也是事务的发起者),在这里它是作为**事务管理器(TM)**的一个角色,负责发起全局事务。
但在 Business 发起全局事务之前,会先请求 TC ,也就是标记1️⃣中的步骤,TC 会生成一个全局事务 XID 并返回给 Business。Business 拿到 XID 之后,才会真正开启全局事务,并且把 XID 透传给下游系统。
Storage 的角色是资源管理器(RM),收到 Business 的请求同时,拿到透传的 XID,此时 Storage 便确认当前的请求是属于哪一个全局事务。然后 Storage 会把自己的事务注册到 TC,作为这个 XID 下面的一个分支事务,然后执行本地事务:扣减商品库存,并且把事务执行结果也告诉 TC,对应标记2️⃣中的步骤。
Order、Account 同样也是作为资源管理器(RM),其执行逻辑跟 Storage 是一致的,步骤3️⃣、4️⃣就不再赘述了。
如果 Storage、Order、Account 事务都执行成功,Business 就会向 TC 发起一个全局事务的提交请求,TC 收到请求后也会同步通知到各个 RM,整个全局事务就结束了。
如果某一个服务执行事务失败了,那么 Business 就会向 TC 发起全局事务的回滚请求,TC 收到请求后也会同步通知到各个 RM,而 RM 会执行相应的数据回滚操作。
架构流程
到这里我们应该大概了解 AT 模式在业务上的流程。由浅入深,从具体到抽象,我们再从全局的视角来看一下。
Seata 设计上将整体分成三个大模块,分别是 TM、RM 和 TC。
- 事务协调器(TC):Transaction Coordinator,监视每个全局事务的状态,负责全局事务的提交和回滚。
- 事务管理者(TM):Transaction Manager,向TC发起,提交,回滚全局事务的请求。
- 资源管理器(RM):Resource Manager,服务向TC发起,提交,报告分支事务的请求,并且服务本地事务的回滚,提交。
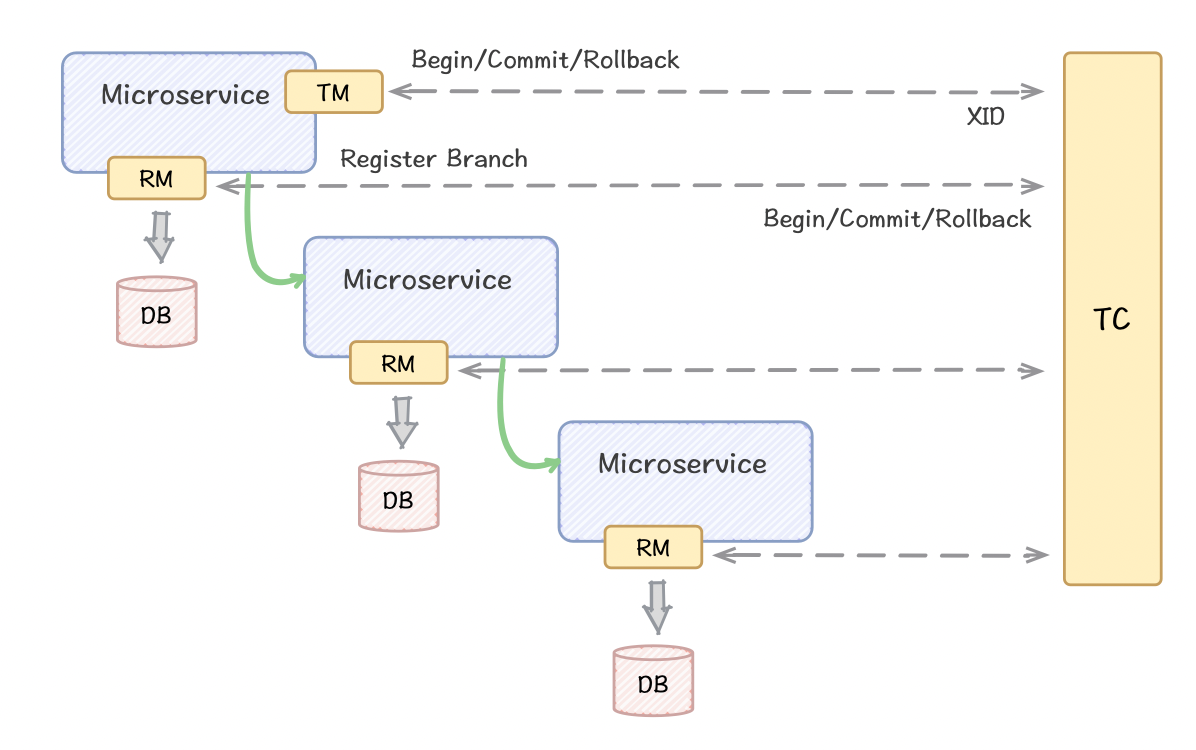
其中 TM 和 RM 是作为 Seata 的客户端与业务系统集成在一起,TC 作为 Seata 的服务端独立部署。
在 Seata 中,分布式事务的执行流程:
- TM 开启分布式事务(TM 向 TC 注册全局事务,获取全局事务XID)
- 调度 RM 业务服务(RM 向 TC 注册,并通知分支事务执行结果 )
- TM 收到结果,事务一阶段结束(TM 通知 TC 提交/回滚分布式事务)
- TC 汇总事务信息,决定分布式事务是提交还是回滚;
- TC 通知所有 RM 提交/回滚 资源,事务二阶段结束;
实现方式
正如上面说的,AT 模式的核心思想是基于二阶段提交而实现的。
一阶段
TM 在开启分布式事务时,会向 TC 注册并生成一个全局事务的 XID。然后 XID 会通过微服务的调用链路透传下去到各个 RM。
RM 在执行分支事务时,Seata 通过代理数据源,拦截业务 SQL,并解析 SQL 语义,生成 SELECT 语句,把要被修改的记录先查出来,保存为 before image,然后执行业务 SQL 更新业务数据,执行完后再将更新后的数据,保存为 after image。这里其实就相当于一个 undolog,保存数据变更前后的记录。
然后 RM 会向 TC 注册分支事务,TC 同时校验并添加行锁(这里也就是对应官网中全局事务 tx1提交前,尝试拿该记录的全局锁的步骤)。
这里可能有的同学对添加行锁的操作就会有疑问,这是什么东西?别急,下面会讲解,这里就可以先理解为,就是获取全局锁的一个操作。
这个是为了防止其他全局事务相同的分支事务的重复操作同一个表同一行数据。
获取全局锁成功后,RM 就提交本地事务,也就是 undolog 和 业务数据一并提交。这些操作都是在一个数据库事务内完成,这样能够保证当前这一个 RM 分支事务的原子性。
划重点:一阶段后,RM 的本地事务都是已经提交了。

二阶段
整个全局事务执行结果只有两种情况,要不就是成功,要不就是失败。成功,是必须所有分支事务都执行成功。换句话说,只要其中一个分支事务执行失败了,全局事务都是失败的。
所以二阶段是有两种:
- 二阶段提交
- 二阶段回滚
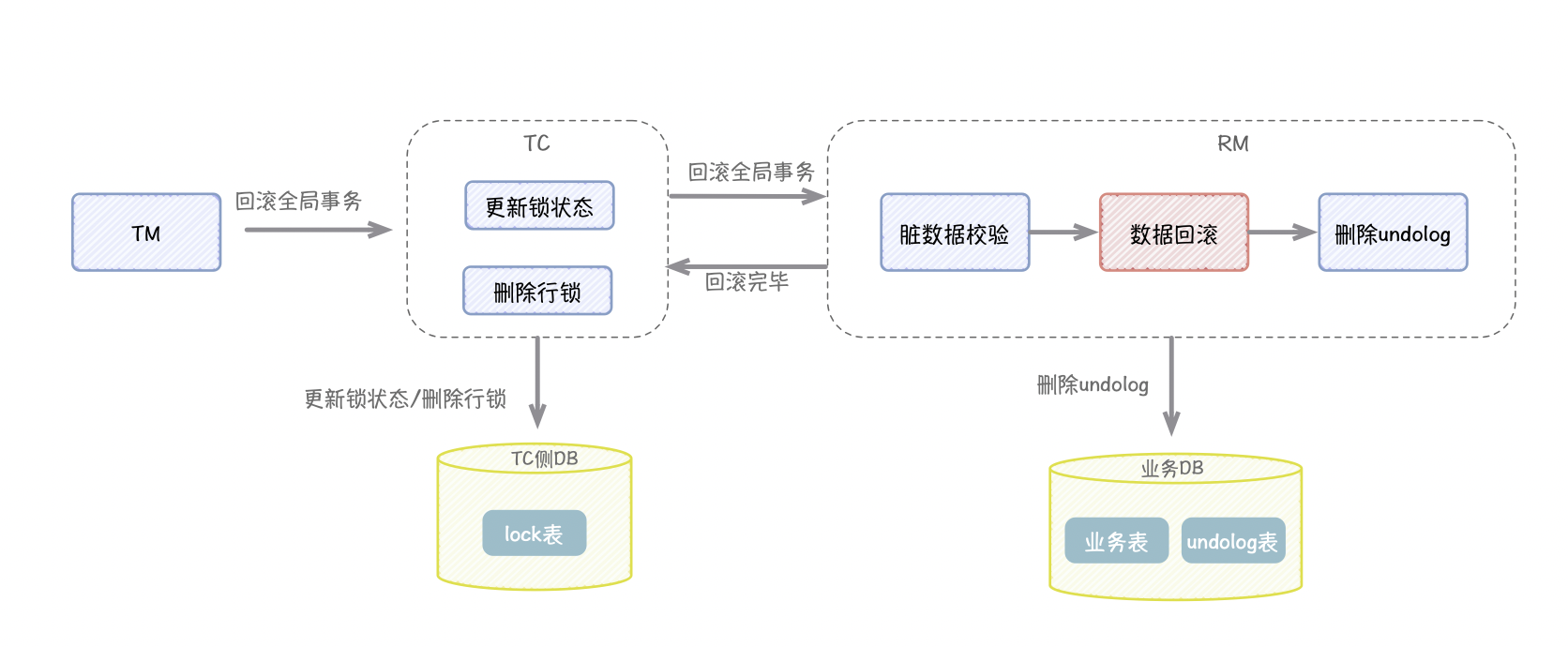
对于 TM 来说,一阶段完成并且未抛出异常,也就意味着分支事务都执行并提交成功,TM 会向 TC 发起全局事务的提交请求,而 TC 就会删除行锁(也就是相当于释放了全局锁),然后通知 RM 异步删除 undolog。

如果有任何的一个分支事务执行失败,对于全局事务来说,都是需要回滚所有的操作。在一阶段中,各个 RM 的分支事务都是已经提交了的状态,那么我们如何回滚事务呢。
这时我们在一阶段中的 undolog 就发挥了作用,还记得我们的 undolog 记录了 before image 和 after image吗?before image 就是我们需要还原到此版本的数据。
当然,在还原数据之前,还需要用 after image 与现有数据库中的数据进行脏数据校验。因为在一阶段提交后,到二阶段回滚的这段时间,该数据有可能被其他业务改动过。假如数据不一致,则说明有脏数据,这时就需要人工进行处理了。
二阶段的提交和回滚,都是异步化的
至此我们已经初步了解了Seata的AT模式是如何实现的。现在再看回官网的介绍,应该可以更容易的理解了。
关于 AT 模式的代码用法操作,可以参考官网文档,简单概括以下几点:
- 在业务入口方法增加全局事务注解
@GlobalTransactional - 配置 Seata 的代理数据源
- 新建 undo_log 表(用于记录
before image和after image)
问题 Q & A
仔细思考上述的过程,其实还是会有不少的一些疑问和困惑。
1. Seata框架,如何保证事务的隔离性?
我们从读写两方面来看:
(1) 写隔离
上面也说过,Seata 会对 SQL 进行拦截,当然并不是所有的 SQL 都会拦截。不过对于写操作的 SQL 都是会拦截的,并且在 RM 提交本地事务前,会向 TC 获取全局锁。在 TC 侧会通过当前分支事务的SQL所生成的一个 LockKey,判断当前有其他分支事务已经持有了相同的锁(即其他事务也在处理相同表的同一行),如果没有则获取全局锁成功,否则返回失败。
未获取到全局锁的情况下,不能进行写,以此来保证不会发生写冲突。所以说,通过全局锁可以避免脏写的问题发生。
(2) 读隔离
在数据库本地事务隔离级别 读已提交(Read Committed) 或以上的基础上,AT 模式的默认全局隔离级别是 读未提交(Read Uncommitted) ,这个怎么理解呢?
这里的读未提交是从全局事务的视角来看的。我们知道,在一阶段后,RM 的分支事务其实已经提交了,这时候在数据库层面来说就是读已提交,但是站在整个全局视角来说,只要二阶段还没执行提交或者回滚,整个全局事务都是处于未提交的阶段。
举个例子,有两个全局事务 tx1、tx2。tx1 读库存为 100,tx1 扣减库存 1,此时 before imgge 为 100,此时 tx2 也同时进来读取库存也为 100
那么问题了就来了,如果 tx1 二阶段回滚,不管 tx2 扣减多少库存,都会覆盖掉 tx2 扣减的库存,出现脏写的情况。
目前 Seata 的方式是通过 SELECT FOR UPDATE 语句的代理,Seata 会对 SELECT FOR UPDATE 语句进行拦截,会先去查询全局锁, 如果 全局锁 被其他事务持有,则释放本地锁(回滚 SELECT FOR UPDATE 语句的本地执行)并重试。这个过程中,查询是被 block 住的,直到 全局锁 拿到,即读取的相关数据是 已提交 的,才返回。
出于总体性能上的考虑,Seata 目前的方案并没有对所有 SELECT 语句都进行代理,仅针对 FOR UPDATE 的 SELECT 语句。
2. 如果其中一个事务分支超时未提交
Seata的全局事务超时时间,默认是1分钟。当 TC 检测到有超市的全局事务时,会向所有已提交分支事务的 RM 发起回滚
3. 客户端是如何实现拦截 SQL、生成 undolog
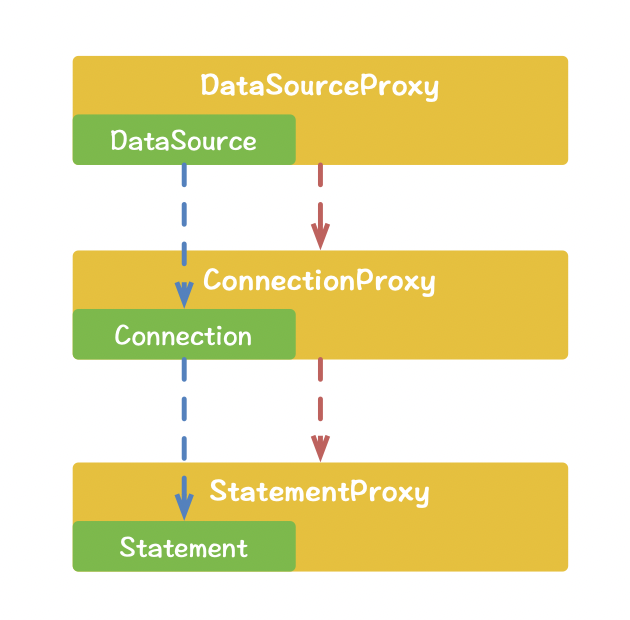
其实也不难发现,简单来说,就是对 JDBC 数据源作了封装代理的处理,对 DataSource、Connection、Statement 都分别做了代理处理。
4. 支持哪些 RPC 框架
目前支持 Dubbo、Spring Cloud、Motan、gRPC、sofa-RPC、EDAS-HSF 和 bRPC 框架。
优缺一谈
Seata 还有 TCC、Saga、XA 模式,因为还没有谈到其他模式,所以我们先简单总结一下 AT 模式的一些优势与缺点,后面等其他模式都介绍完了,我们再来一个综合的横向对比。
优点
- 简单易用:从上面的介绍我们也知道,整个AT模式有三个模块 TC、TM、RM。其中 TC 是单独部署的服务,官网也有非常健全部署方案。而 TM 其实在代码层面来说就是一个注解的事情,RM 甚至都不需要做任何操作,Seata 客户端都自己封装好了。所以 AT 模式对于代码侵入性是非常小的。
缺点
- 性能:
- 在事务过程中与涉及多次的 RPC 远程调用,SQL 的解析以及 undolog 这些都是额外的消耗。
- 锁冲突,通过全局锁来解决不同全局事务之间的读写冲突,而全局锁只有在第二阶段提价或者回滚后才会释放,锁的粒度比较大。如果对于并发量大的业务,或者是热点数据的读写,会有并发的性能问题。
- Seata 底层依赖与业务的数据库,因此 Seata 客户端需要适配各个 DB 厂商不同的 DB Driver(数据库驱动),不过目前来说,已经适配了市面常用的主流数据库,如果你用的不是非常偏非常小众的DB 的话。
- AT 模式下,默认的数据库隔离级别是: 读取未提交。这一点需要注意,在涉及到强一致性的读,需要加上全局锁,否则会出现脏读。
总结
AT 模式的核心思想,通过二阶段提交,从而实现分布式事务。也通过结合具体的使用场景,更加深刻的了解 AT 模式的原理和实现方式。
总的来说,AT 模式对比与其他模式来说,使用其实是最为简单易用的。因为复杂的逻辑处理都有客户端处理而屏蔽掉,但也因此在扩展性、性能等方面上也有一定的限制。
分布式事务本身就是一个非常复杂问题,面对的纷繁复杂的业务模式和架构,需要切身结合实际的业务场景具体分析。
没有最好的,只有最合适的。
