

系统的复杂度,会随着业务的发展而越高。当业务发展到一定的阶段,原本单一的业务系统可能无法支撑或者出现瓶颈时,就需要对此进行重新规划和设计。
最近,小年就碰到这个问题,原本业务的下的一些子业务最近发展比较快速,经过大家的讨论后,决定将这些子业务重新规划,拆分出单独的业务系统,目的也是为了方便日后的迭代和扩展。
具体情况具体分析,由于我们涉及拆分的业务,在业务量上比较大,并且面向C端用户,需要确保可用性。所以整体的迁移方案复杂度也会比较高。
我们是将拆分迁移分为两个阶段:应用拆分、数据拆分。
应用拆分
应用拆分,目标是将需要拆分的业务代码剥离出来,独立的应用系统,并且将拆分业务的流量都访问到这个新服务上。
当然,我们第一步必须要进行业务梳理。这里我将工程拆分迁移的内容划分为是三个部分:API、消息队列、定时任务。
API
一般来说,工程里的入口都是以 API 的形式提供出去,所以我们最容易想到的就是 API ,但同时这也是最比较复杂和繁琐的。
从类型层面可以分为:
-
外部接口:一般是前端调用,比如H5、小程序、APP客户端等。
-
内部接口:指服务之间的调用,提供给其他业务系统调用的。提供的方式通常是 HTTP 或者是 RPC。
外部接口一般都是通过统一网关透出去的 HTTP 接口,如果有接入统一网关,并且统一网关提供切流功能,我们可以平滑的把流量迁移到新的服务中。
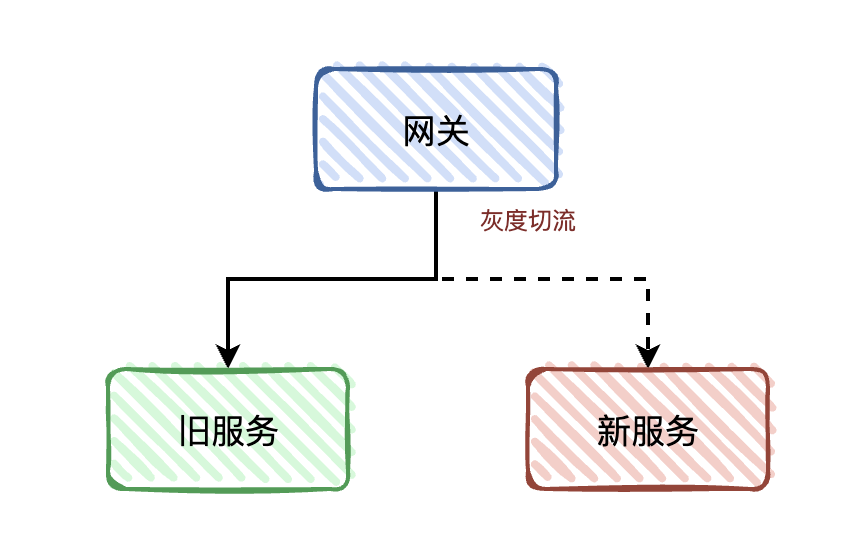
这操作对于前端来说都是无感知的,甚至都不需要改动任何的接口。这一点很重要,因为对于一些前端没办法更改接口的情况,比如 APP 客户端,用户使用的旧版本 APP ,你肯定是没办法对其做任何修改,这种情况是需要兼容的。
内部接口,如果是 HTTP 接口并且也接入统一网关那好说,跟外部接口同样的切流方式是一样的。如果是 RPC 接口的话,要做到平滑切流,理论上有点麻烦。因为目前项目还没有 RPC 接口,所以暂时没有好的更具体的落地方案。
从业务层面可以分为:
- 独立接口:只有拆分业务单独使用
- 耦合接口:拆分业务和其他业务共用的
独立接口的迁移比较简单,直接迁移到新服务中,再通过网关灰度切流即可。而对于耦合类型的接口,这部分处理起来就比较麻烦。不过也分情况,如果接口参数能够区分业务的话,那么可以在网关转发的时候判断处理,前提是网关能够支持自定义脚本的功能,就是在网关层面能够解析参数,再做转发。
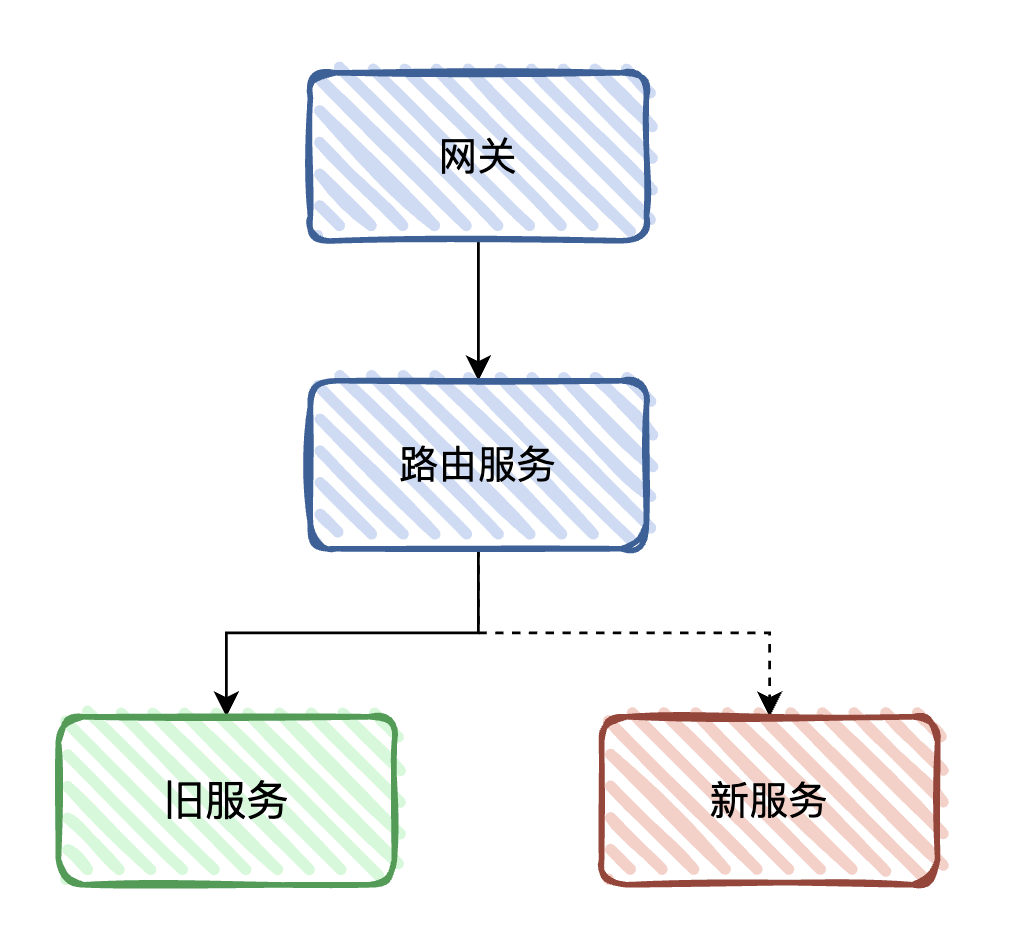
不过如果网关不支持,或者判断的逻辑是在业务代码里面,我们可以考虑加一层路由转发的服务。
消息队列
服务之间的数据同步和通讯,通常会用到消息中间件。在服务拆分迁移中,我们需要考虑的有 Producer 和 这两种情况。
这里主要讨论的是 Consumer 的迁移方案,因为 Producer 一般都是通过接口触发,在上面 API 迁移的时候我们其实已经相当于迁移完成了。
我们还是举个例子:原本用户系统和积分系统是在一起的,并且用户系统和积分系统都需要订阅订单消息,更新各自的业务数据。
假设现在把积分系统拆分出来,就是说会存在两个应用会监听订阅订单 Topic,两个服务都是不同的消费集群。那么问题就来了,现在的情况是:原有的用户系统里面还会继续保留积分的逻辑,当订单消息过来的时候,两个系统都会对其做处理。也就是说,两个系统都会对同一条积分数据处理。
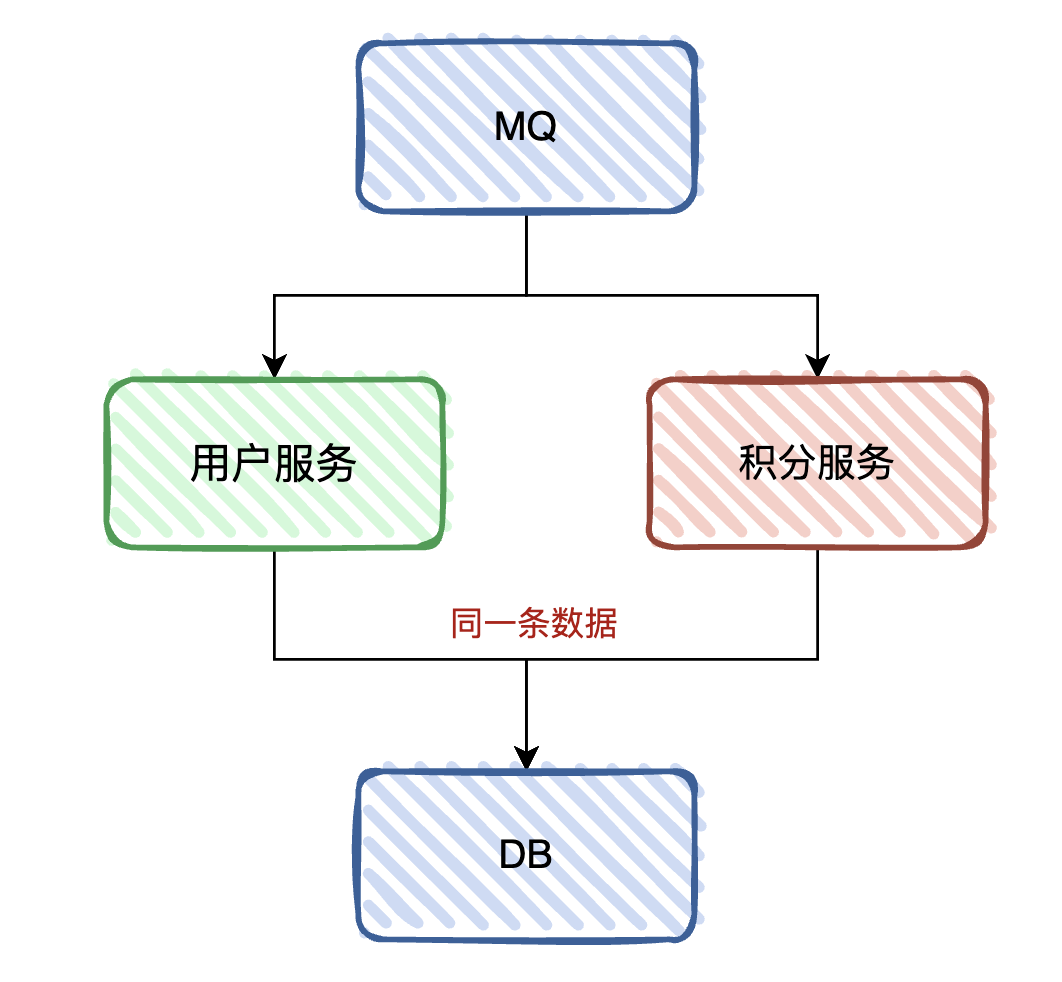
首先,为什么不能把用户服务上积分消费的逻辑移除掉呢?
因为如果积分服务出问题了,而用户服务又把原有的积分逻辑给删掉了,那么不就没有回滚的退路了吗?
如果说业务体积量不大的话,直接迁移就得了,但是如果业务量一旦非常大,并且涉及核心的数据,比如订单这类的,那我们就需要能够灰度回滚的方案。
聪明的同学就会说,加个分布式锁或者数据库锁不就可以解决了吗?
确实,这也是最为简单直接的方式,这样子可以避免用户服务和积分服务重复操作同一条数据,况且消费者在处理的时候自身一般也会做幂等处理。还可以在积分服务中的消费端,加上控制开关,如果积分服务消费出问题,可以通过开关关闭消费逻辑。
数据拆分
在做完应用拆分之后,我们目前的应用结构应该是这样子:
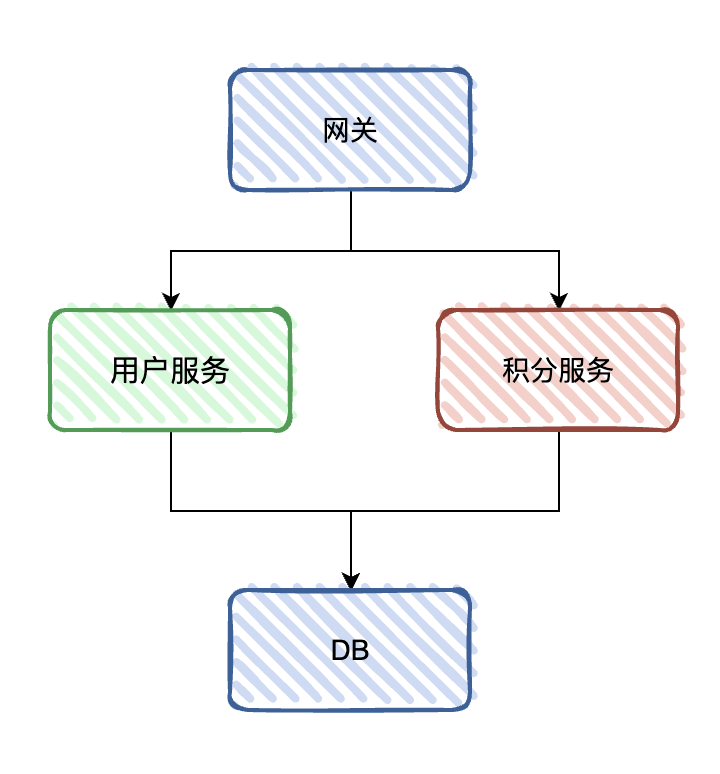
流量已经都独自隔离开来了,但仍共用同一个数据库。按照微服务体系架构,服务之间的数据也是需要隔离开来的。所以我们下一步的目标是,把拆分业务的数据迁移到新的数据库上,才算是真正的完成整个服务拆分。
同样,在迁移之前我们先要需要梳理,目前服务用到哪些数据库和表,每个表的数据量有多少。这一步很重要,因为不同数据库类型,数据迁移和同步上可能有不同的方式;数据库表的数据量大小,也决定我们所采用哪种迁移方案。
一般来说,我们会基于业务读写频率和业务优先级来划分。比如订单表、用户表等这些必然是大表,且读写频率极高的;而配置表、流水表等这种读写频率可能就没这么高。
要综合考虑到人力成本和时间成本,对于读写频率低的数据表,建议可以采用在低峰期直接切换的方式,一步到位。而对于读写频率高,且数据量大的,此时我们就需要考虑更加稳妥安全的迁移方案。
以小年所做的项目为例子,数据库主要用到的是 MySQL、MongoDB,涉及到的数据库表最大的有2kw+(这里是没有做分库分表),同时也是读写频率高,业务优先级最高的一张表。
对于不同数据库之间的数据同步,现在其实已经有很多成熟的方案和工具,比如 MySQL,可以Cannal
实现,而且云产商也有提供相应的DTS服务,更加方便。而 MongoDB 可以用 MongoShake 实现。
但是这些同步的方式其实都有一个问题点,只能单向同步,这意味着什么呢?
假设,我们数据流量切到新数据库上,也就是把新应用切换到新数据库,在运行一段时间后发现新数据库出问题或者数据不对。正常来说,我们是马上把新应用切换回旧的数据库。但是,这段时间新库上新增的数据(增量数据)是不会同步回旧库的,这样子就会存在数据不一致性的问题。
所以,我们数据迁移的方案不仅仅是完成数据的迁移,更需要考虑到在迁移至新库的过程中,做到可灰度,可回滚。
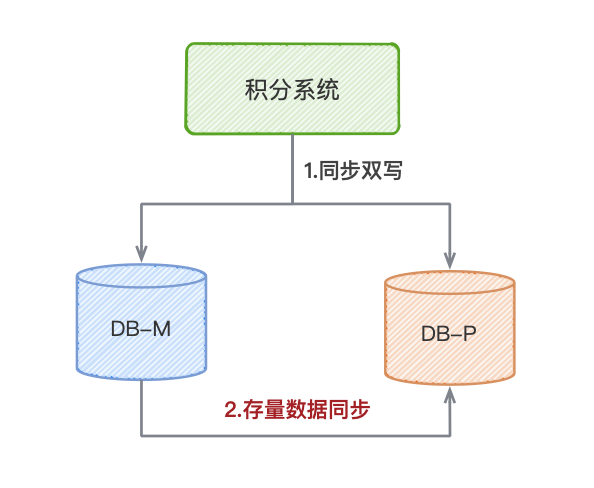
1. 数据双写
第一步,我们采用数据双写。在写入旧数据库中的同时,也往新数据库写入。当然,这里是避免不了要对涉及到数据层写入的代码开发。

同步双写
写入旧库后,再同步写入新库。
-
优点:能够保持两边的数据一致性
-
缺点:影响业务性能耗时,并且新库写入失败,会影响业务流程。
这一点是需要注意的,我们都必须要保证不影响写入旧数据库的整体业务流程,不能因为加入了新库的写入代码,导致业务流程出问题。
异步双写
写入旧库后,再异步写入新库。
- 优点:不影响原有业务流程。
- 缺点:数据延时,可能会丢失,数据不一致性可能性比较高。
But,异步写的一个问题点是,取决于业务是否有顺序的要求。比如订单场景,需要先创建,再更新。那么如果是异步,在极端的情况下,更新请求会可能会比创建请求先到达,那么更新写入就会失败。
所以我们就需要控制异步的顺序,比如借助消息中间件的顺序队列,根据订单号做shade key,保证同一个订单的业务顺序。也就是说,我们还需要实现消费端把数据写入新库,操作是相对麻烦一点。
当然,如果没有顺序的要求,那么异步线程其实也是够满足的。
2. 存量数据同步
开启双写之后,就意味着新旧数据库的增量数据是一致的,我们就可以开始着手于存量数据的迁移了。
MySQL 的全量数据同步方式有很多,数据库表直接导入、Canal、云厂商的DTS等,MongoDB 则是采用阿里云自研的 MongoShake。
需要注意的是,如果业务上是需要ID作为业务关键字的话,要避免跟增量数据的ID重复。比如,新库上增量数据的ID不允许跟旧库存量数据的ID重复。
3. 数据校验
数据双写的阶段会出现数据不一致性的情况,因为操作的是两个数据源,应用的事物不能保证事务一致性。尤其是异步方式的双写,数据不一致的概率性可能会更高。
数据校验的实现其实也并不复杂,一般来说以旧库的数据为准,对比新库数据的数据是否有不一致地方。至于具体对比哪些数据,什么时候执行数据校验,就根据业务需求自行评估。
一般来说都是通过定时任务,选在低峰期执行。
4. 流量切换
到这一步,新库的数据已经跟旧库基本一致了。也就是说,新库的数据写入已经完成了。那么接下来就是要对将读流量迁移,新库的数据写入是不会影响业务,但是读数据如果切换到新库出问题,所以我们需要考虑可灰度的方案。
简单来说,我们需要在项目工程上接入多个读数据源,并根据灰度策略判断读取旧库或者新库的数据。也就是说在数据源这一层上,我们需要增加一个路由层来决策,是走哪一个数据源。
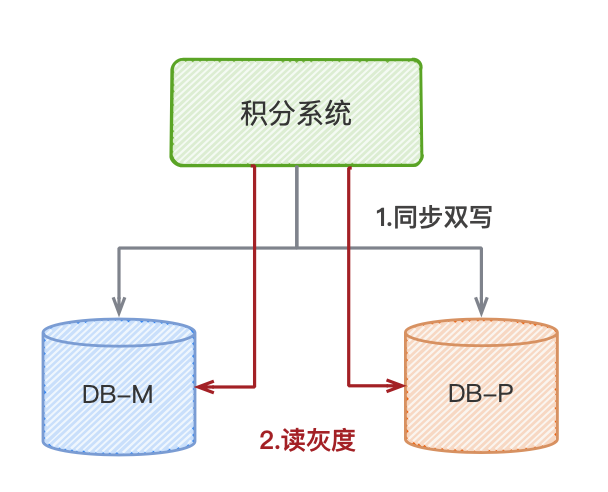
至于灰度的策略需要根据具体的业务具体分析,一般来说,可以根据用户的memberId、订单的orderNo 等取100的模,控制灰度比例,小年就是采用这种方式实现的。
rate = shade_key mod 100
sharding-jdbc 可以支持接入多数据源,并且可以自定义路由规则。
等到读流量完全切到新库上,那就意味着新库的数据读写已经是没问题了,也就是完成了数据库的迁移了。
总结
服务的拆分迁移方案大致就是这样子,因为拆分的业务比较复杂,我们分为两个阶段:应用迁移、数据迁移。
应用迁移,目的是将业务拆分成独立的工程,并且将业务对应的流量迁移到到新的服务上。
数据迁移,将拆分业务的数据迁移到新库上,并且将新服务的数据源也随之切到新库。数据迁移这部分的方案其实也适合。
总的来说,整个拆分计划比较复杂繁琐,具体要落实是需要一定的人力和时间。所以一定需要对业务进行合理评估,如果说不是一定需要严谨的设计,建议还是一切从简。